
At the present time, Data is the need of the world. Each day we are creating 2.5 quintillion bytes of data in the present era, and that’s huge.
You probably are wondering how this much amount of data is generated. You visit the internet daily and search over the internet for related stuff, listen to music, and watch videos. Moreover, you use social media, upload photographs, share your thoughts and posts.
Even with each Tinder swipe, you are directing some data to the servers. With each Snapchat or Instagram upload, there is a whole lot of data being stored somewhere. Your chats (on whichever platform they are) also contribute to making the data this much large.
But, do we do not need each and every data unit. We need the appropriate information only that is of use to us. At the end of the day, data on its own is of no use. However, the data that is arranged in a meaningful manner turns into information and we need the information.
The process by which we convert the raw data into meaningful information is known as data processing.
Jump to Section
Data Processing

It is an operation performed over data (raw facts) to manipulate and convert the data into meaningful information.
Data processing involves 3 activities:
1- Input
In this process, the data that is collected is transformed into a form that the computer can understand.
It is the most important step because the output or the result depends completely on the data that is provided as the input.
The data input process involves the following set of activities:
- Collection: We gather the raw data from various data sources and prepare it for the input process.
- Encoding: We convert the collected data into a form that makes it easier to put the data into a data processing system.
- Transmission: We send the input data to the various processors and carry it across various components.
- Communication: A set of activities that allow the sending of data from one data processing system to another.
2- Process
It is the process of transforming raw data into information by performing some actual data manipulation techniques.
The techniques that we use in the process stage are as follows:
- Classification: In this stage, we classify the data into different groups and subgroups so that it is easier to handle the data.
- Storing: In the storage technique, we store the data in an arranged order so that we can access it quickly whenever we need it.
- Calculation: We apply this technique to the numeric data to calculate the required output from the raw figures.
3- Output
The information that we get as a result of the data processing is the output. We can present the output information in a visual form and can take further actions or make some decision on the basis of the output.
Challenges in Data Processing
Until now, we have understood the difference between data and information. Moreover, we came to know how data processing works.
But, it is not as simple as it seems. There are several challenges that come while processing the data. Let me put some light on the key challenges that appear while processing the data.
1- Collection of data

The very first challenge in data processing comes in the collection or acquisition of the correct data for the input. We have the following data sources from which we can acquire data:
- Administrative data sources,
- Mobile and website data,
- Social media,
- Tech. support calls,
- Statistical surveys,
- Census,
- Purchasing data from third parties.
There are many more examples. Sometimes, the data collection agent walks door to door to collect the data that we need, which is rare but still happens.
The challenge here is to collect the exact data to get the proper result. The result directly depends on the input data. Hence, it is vital to collect the correct data to get the desired result.
Solution
Choosing the right data collection technique can help to overcome this challenge. Below are the 4 different data collection techniques:
- Observation: Making direct observation is a quick and effective way to collect simple data with minimal intrusion.
- Questionnaire: Surveys can be carried out to every corner of the globe. With them, the researcher can structure and precisely formulate the data collection plan.
- Interview: Interviewing is the most suitable technique to interpret and understand the respondents.
- Focus group session: The presence of several relevant people simultaneously debating on the topic gives the researcher a chance to view both sides of the coin and build a balanced perspective.
2- Duplication of data
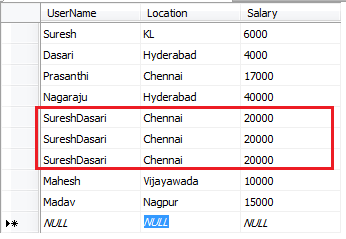
As the data is collected from different data sources, it often happens that there is duplication in data. The same entries and entities may present a number of times during the data encoding stage. This duplicate data is redundant and may produce an incorrect result.
Hence, we need to check the data for duplication and proactively remove the duplicate data.
Solution
Data deduplication is adapted to reduce the cost and free storage space. Deduplication technology of data identifies the identical data blocks and eliminates redundant data.
This technique significantly reduces the size of disk usage and also reduces the disk IO traffic. Hence, it enhances the processing performance and helps in achieving precise and high accuracy data.
3- Inconsistency of data
When we collect a huge amount of data, there is no guarantee that the data would be complete or all the fields that we need are filled correctly. Moreover, the data may be ambiguous.
As the input/raw data is heterogeneous in nature and is collected from autonomous data sources, the data may conflict with each other in three different levels:
- Schema Level: Different data sources have different data models and different schemas within the same data model.
- Data representation level: Data in different sources are represented in different structures, languages, and measurements.
- Data value level: Sometimes, the same data objects have factual discrepancies among various data sources. This occurs when we obtain two data objects from different sources and they are identified as versions of each other. But, the value corresponding to their attributes differ.
Solution
In this situation, we need to check for the completeness of the data. Also, we have to see the dependency and importance of the field (inconsistent field) to the desired result. Furthermore, we need to proactively figure out bugs to ensure consistency in the database.
4- Variety of data
The input data, as it is collected from different sources, can contain different forms. The rows and columns of a relational database don’t limit the data. The data varies from application to application and source to source. Much of this data is unstructured and cannot fit into a spreadsheet or a relational database.
It may be that the collected data is in text or tabular format. On the other hand, it may be a collection of photographs and videos and sometimes maybe just audio.
Sometimes to get the desired result, there is a need to process different forms of data altogether.
Solution
There are different techniques for resolving and managing data variety, some of them are as follows:
- Indexing: Different and incompatible data types can be related together with the indexing technique.
- Data profiling: This technique helps in identifying the abnormalities and interrelationship between the different data sources.
- Metadata: Meta description of data and its management helps in achieving contextual consistency in the data.
- Universal format conversion: In this technique, we can convert the collected data into a universally accepted format such as Extensible markup language (XML).
5- Data Integration
Data integration means to combine the data from various sources and present it in a unified view.
With the increased variety of data and different formats of data, the challenge to integrate the data becomes bigger.
The data integration consists of various challenges that are as follows:
- Isolation: The majority of applications are developed and deployed in isolation which makes it difficult to integrate the data across various applications.
- Technological Advancements: With the advancement in technology, the ways to store and retrieve data changes. The problem here occurs in the integration of newer data with legacy data.
- Data Problems: The challenge in data integration rises when the data is incorrect, incomplete, or is of the wrong format.
Then we have to figure the right approach to integrate the data so that the data remains consistent.
Solution
There are mainly three techniques for integrating data:
- Consolidation: It captures data from multiple sources and integrates it into a single persistent data store.
- Federation: It gives a single virtual view of multiple data sources. When it fires a query it returns data from the most appropriate data source.
- Propagation: Data propagation applications copies data from one source to another. Furthermore, it guarantees a two-way data exchange regardless of the type of data synchronization.
6- Volume and Storage of data

When processing big data, the volume of the data is considerably large. Big data consists of both structured and unstructured data. This includes the data available on social networking sites, records of companies, data from surveillance sources, research and development data, and much more. Here comes the challenge to store and manage this sheer volume of data. Another challenge is what amount of data is to present to the RAM so that the processing is faster and the resource utilization is smart.
Also, we need to back up the data to ensure it is protected from any sort of loss. The data loss could occur due to software or hardware issues, natural disasters, or human error.
Now, the data itself is huge in volume and we need to take a copy or backup of the data for safety. This increases the amount of stored data by up to 150% or even more.
Solution
Below are the possible approaches that we may use to store a large amount of data:
- Object storage: with this approach, it is easier to store very large sets of data. It is a replacement for the traditional, tree-like file system.
- Scale-out NAS: is capable of scaling the capacity of the storage. It usually has its own distributed or clustered file system.
- Distributed nodes: most often the low-cost commodity implements this. It attaches directly to the computer server or even server memory.
7- Poor Description and Meta Data
One of the major sources of the input data is the data that is stored over time in a relational database. But this data is not properly formatted and there is no meta description of the storage, structure, and relation of the data entities with each other.
The scenario becomes even worse when the amount of data is large and the database itself links to other databases. Without proper documentation of the database, it is quite difficult to extract the correct input data from the databases.
Solution
- De-normalize the database for querying purposes.
- Use the stored procedure to allow complex data management tasks.
- Using a NoSQL database for storing data
8- Modification of Network Data
The data is distributed and simultaneously related to each other in a complex structure. The challenge here is to modify the structure of the data or add some data to it.
The internet is a network that consists of a variety of data, a lot of applications and websites generate data that are all of different forms and characteristics. Schema interconnects all of them.
A schema is the definition of the indexes, packages, table/rows, and meta-data of a database.
It is difficult to transport data if a database doesn’t handle Schema.
Solution
Server Data Tools (SDT) includes a schema compare utility that we can use to compare two database definitions. The SDT can compare any combination of source and target databases.
Moreover, It also reports any discrepancies between schemas and detects mismatching data types and defaults of columns.
9- Security

Security plays the most important role in the data field. Hacking the data might result in a data leak. Hence, it may cost highly to the data processing firm. The hacker might even change or delete the data that we have acquired and processed after a lot of struggle.
The reasons for the security breach in a database are mainly due to these reasons:
- Most of the data processing systems have a single level of protection.
- No encryption of Either the raw data or the result/ output data.
- Access of the data to unethical IT professionals that present a risk for data loss.
Solution
To ensure the security of the data we should follow the below-mentioned practices:
- Do not connect to public networks;
- Keep personal information safe and secure with a strong password;
- Limit the access of humans to the data;
- Encrypt and back up the data.
10- Cost
Cost is a matter of consideration. When the amount of the data increases, then the cost in each stage of the data processing increases gradually.
The cost of data processing depends on the following factors:
- The type of processed data;
- Turn around time to complete the processing of data and get the required result;
- The accuracy of the data;
- Workforce working on data processing.
Solution
The stakeholders or the management looking into data processing must consider the budget and the expenses. Compressing the data reduces its size and thus the data occupies less disk space. With proper planning of the costs and expenses, the firm could earn well with the data processing service.
Conclusion
To conclude, the above-stated points are the biggest challenges that a data processing firm would face. Data processing will become more sophisticated once these challenges are hammered out. There is also a need for a highly skilled and motivated workforce to extract out the best result.
I excel when it comes to making bespoke data dashboards and visualizations that users and clients absolutely love. Sharing about things I enjoy doing is my hobby, whether it's about a project, collaboration, feedback, or just simple how-to guides about visualization.
If you have something to ask or share, I'd love to hear from you!
- Business Intelligence Vs Data Analytics: What’s the Difference? - December 10, 2020
- Effective Ways Data Analytics Helps Improve Business Growth - July 28, 2020
- How the Automotive Industry is Benefitting From Web Scraping - July 23, 2020