
Jump to Section
What is Netflix?
Netflix is an online media service provider that gives a platform to watch all famous TV Shows, Awards, Documentaries, Flims, and much more entertainment on a broad level. Netflix as a big brand is improving itself very fast these days because of its attracting features and entertainment media. It also provides one month free trial for every new user. But after one month you will be charged as per the plan.

Netflix contains big database compared to other media service providers like Amazon prime video, HBO, and Hulu. It is a big name in the world of the online entertainment industry. It was founded by Reed Hastings and Marc Randolph. Netflix is used worldwide and even you can download any media which you like in it. Now, if we talk its data processing work then Netflix is very fast and robust in processing the data online.
Two major ways of processing the data in Netflix
How data is Processed using Chukwa/Kafka in Netflix?
Netflix is a big data-driven organization and many products and business decisions are totally based on data analysis. In this article, you will understand the evolution pipeline of Netflix. The pipeline is mainly used to collect aggregate data and move that data on a cloud scale. Once you click on any media service Netflix starts processing data in less than of a nanosecond. Every time you watch new application or shows it process the data in several terms. Netflix provides almost 500 events that consume 1.3 PB/day and 8 million event that consumes 24 GB/Second during peak time.
There are more several events that flow through the giant pipeline like as
- Error logs
- UI activities
- Performance events
- Video viewing activities
- Troubleshooting and diagnostic events
Over the past few years, its data pipeline has taken experienced on major data transformations due to technological developments and evolving requirements as follows
V1.0 Chukwa Data Pipeline
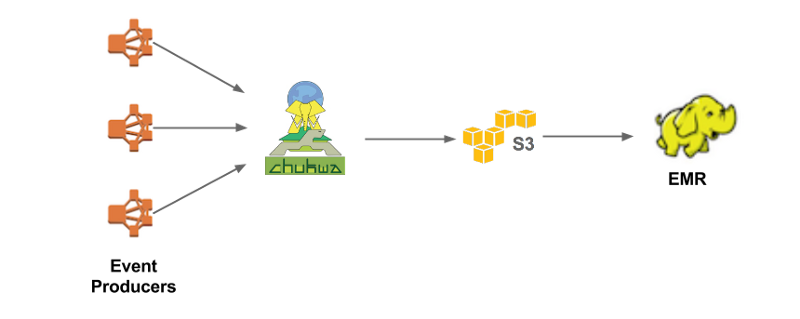
This Chukwa data pipeline was launched to upload multiple online events to Hive/ Hadoop for batch processing. A batch processing is a core fundamental part of data processing. A batch processing segregates the compute flow program without intervention. Now, look at the architecture of Chukwa that collects most of the events (event producers) and writes them in Hadoop file sequence format (S3). Then, further Big Data team processes these S3 Hadoop files and writes Hive in Parquet data format. End-to-end latency time is up to 12 minutes. That is enough for batch processing which basically scan the whole data at the hourly or daily frequency.
V1.5 Chukwa Data pipeline with real-time frequency
In the last couple of years with Elasticsearch and Kafka, it has been a growing emerging demand for real-time data analytics in Netflix architecture. Kafka contains its real name as Apache Kafka. It is a totally open source and stream processing platform. It is written in Java and Scala. Apache Kafka is used to handling the real-time data. Elasticsearch is an open source engine that is based on Lucene. It creates a full text and distributed search engine through HTTP web request.
As a result, to upload online events to EMR/S3, Chukwa can also provide traffic to Kafka (it is the main gate in real-time data processing). In V1.5, around 35% of the live stream events are posted to the real-time of the data pipeline. The centerpiece of the real-time pipeline is the main router. It is much responsible for channelizing the data by using Kafka to the links like as secondary Kafka or Elasticsearch.
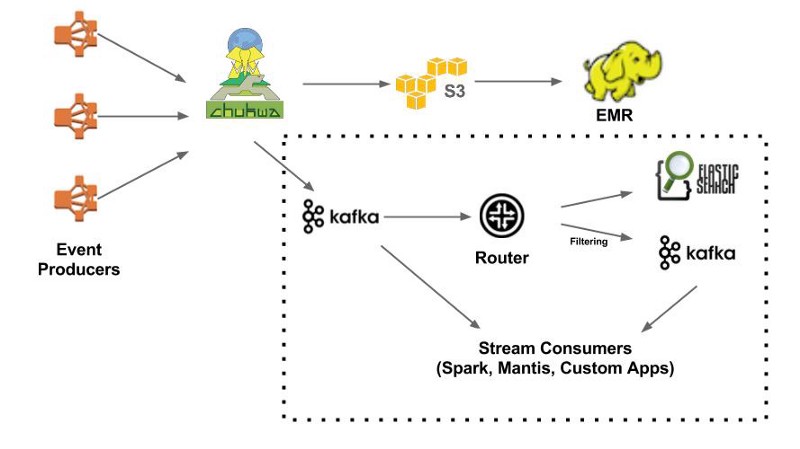
In the last couple of years, we have seen massive growth in Elasticsearch within Netflix. There are approximately 150 clusters totaling, and 3,500 hosts with instances. Chukwa can deliver filtered streams. But sometimes, we apply specific filtering on the Elasticsearch and Kafka streams written in Chukwa. That is the only reason we consider the router to take from one Kafka/ Elasticsearch topic to a different Kafka/ Elasticsearch topic.
Once we deliver final data to Control panel (Kafka), it empowers users to get experience with stream processing like a Spark, Mantis, Custom Application, and Spark. “Responsibility and Freedom” is the DNA of Netflix’s future. It totally depends on the users to select the right path for the task. Because our expertise is our moving data at a large scale, and our data management squad maintains the router just like managed service.
Facts while operating the routing for data service
- The Kafka provides high-level consumer that may lead to loss of partition ownership. So, stop consuming few partitions just after running stable.
- When we create new code, it has been seen that the high-level consumer get stuck in a bad state while rebalancing the routing service.
- We group thousands of routing jobs into small pieces of clusters. But managing these clusters and jobs is an increasing burden on the database. In conclusion, we need a find a better platform to manage all the routing jobs.
Benefits of Chukwa
- Apache Chukwa is a platform that provides flexibility in the formed distributed system and rapid data processing.
- Chukwa is an open source that supports the large distributed collection of data. It is made up of HDLS (Hadoop Distributed File System) technologies and MapReduce framework system.
- Chukwa is the more flexible tool that is used for data analysis and data monitoring.
V2.0 Keystone pipeline (Kafka fronted)
So far, we have seen a lot of issues related to routing service, but there are different motivations for all of us to regenerate our data pipeline. For this reason, you need to simplify the Kafka architecture. Kafka provides replication that improves its reliability and durability. On another hand, Chukwa does not support replication. Kafka has a solid vibrant community with strong communication.
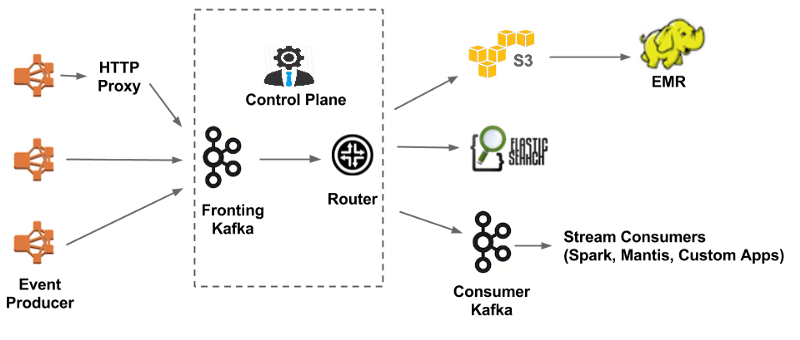
There are three main components as follows:
Data Ingestion
There are two common ways for applications to ingest data as follows
First: use only Netflix Java library and directly write to Kafka.
Second: send an HTTP (Hyper Text Transfer Protocol) proxy which later writes to Kafka.
Data Buffering
Kafka stores temporary data which can be moved from one place to a different place. Buffered data also can be used while moving process and data within a computer. It also helps to consume temporary search from downstream links.
Data Routing
The data routing is a service that is responsible for moving data in the control panel which consists of fronting Kafka and router to many links like as S3, secondary Kafka, and Elasticsearch.
For now, you have seen how Netflix used data and how steps have taken for data processing. If we compare the process of data processing with Amazon and HBO, Netflix won because it covers a very vast and robust process for processing the data in Netflix. Now, we will see look into how it works in real life. Netflix beats Amazon and many other media services because of its simplicity and easiness.
Benefits of Kafka
- Kafka is perfect for storing high-velocity and large-volume of data. Kafka can read thousands of encrypted messages per second.
- It is capable to deal with these encrypted messages with the low latency (range: milliseconds), it is very useful for the new cases.
- Kafka also contains high durability, and reliable. Kafka can also handle the abundance of data without interrupting any downtime.
How data is Processed using Big Data Analytics in Netflix?
Netflix is a website that allows users to watch online streaming like as “Entertainment and Original TV Shows”. Netflix has over 1 Billion subscribers till now and growing very fast as compared to other streaming channels like Amazon Prime and Hulu etc. Now, learn how Netflix uses big data analytics to drive the success. Netflix uses millions of data everywhere in the world. When they launched streaming media service in 2007, that took 7 years to collect the data to predict the success of their first real production ‘House of Cards’. Netflix has come across the world and used data analytics on the right path to get success in business point of view.
As you know, Netflix has over 100 million user base, imagine that how a large volume of data it receives on a daily basis. Netflix has made some events that collect the data in terms of big data analytics. Netflix has a solid team of data scientists which they track records like this as follows.
- It tracks the time when does a subscribed user watch a TV show.
- It also keeps records where does a user watch it and on what device does a user watch because the nature of every TV shows and programme vary with the device either on Desktop, TV or Mobile Phones etc.
- They track when does a user pause a program and It also keep records if they repeat any portion of the current program.
- In the end, it tracks all search and ratings of a subscribed user.
- They collect all these information and provide further in making the business decision. Because this information really helps in building the Netflix TRP (Television Rating Point).
The first series ‘House of Cards’
Netflix provides original media shows like as House of cards. House of cards is a famous and very popular American TV web series, it started first web series in February 1993 with 5 seasons till 2017. HOC is totally based on thriller political drama. HOC divides into two big names Kevin Spacey Films and David Fincher Films. Most of the viewer watched Fincher’s film name ‘The Social Network’ from start to the end.
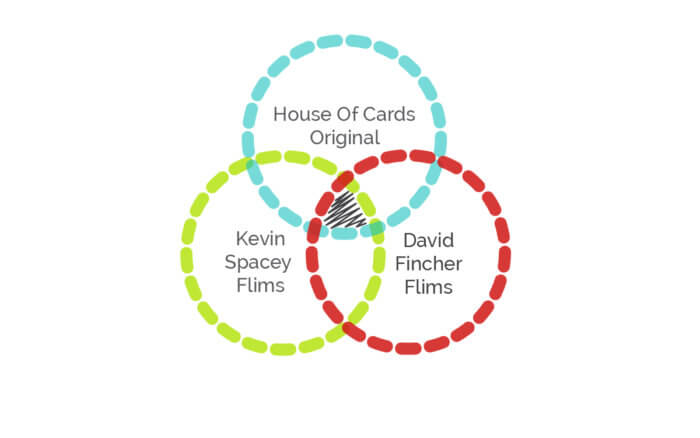
House of cards was divided into two watching patterns for measuring the intersection result. It was easily predicted that this plan would be the super hit. Now, we all know they were right but not only for content creation, they also used big data analytics to enlighten the market show. In conclusion, they have created sections of user experience and made some different films trailers to achieve these sections. Netflix collect all the data of individual sections like as follows
- The user details provided during signing up to the Netflix.
- The series/movies that you marked as like.
- It keeps the record for all the suggestion that you search over a particular action or actress.
- Repeat watching the show of a particular category
- It also tracks accounts for signing as child or adult.
- If we talk realistic, you can not predict how much data the Netflix process.
Netflix: Decision making Data Framework
The image given below shows the data analytics framework at Netflix.
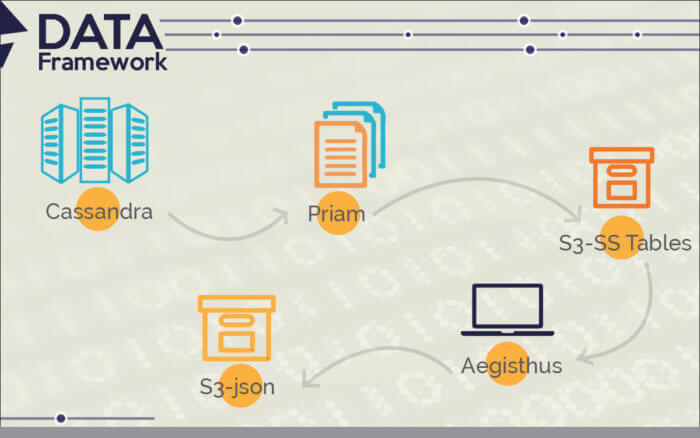
Aegisthus is a place that built Netflix’s data structure which later can be used to work on Hadoop MapReduce in terms to divert from Cassandra’s SSTables to query-able methods.
Analytics has given a top edge as with its all competitors. Surprisingly, Netflix is the only content creation organization who uses analytics and data at this level of scale and content production acquisition. Other competitors use data analytics for only content promotion. Netflix uses data to identifying success rate of a particular show. It really does not need any pilot episodes. Pilot episodes are just sample or temporary episodes for new concept programs. Netflix’s original TV shows success rate is increasing around 80% as compared to other traditional shows around 30%-40%. Netflix also uses big data on advertisement and suggested TV shows to premium users that really helped in its promotional budgets.
Note: Netflix provides a free trial for one month. After one month you will be charged as per the plan you choose. It also provides several plans like as Basic plan that user can use only on one screen at a time. Standard plan, that user can use two screens at the same time. Premium plan, that user can use on 4 screens. For more clarification refer to the image given below.
Netflix and its competitors
- In addition with Amazon prime, Netflix is playing a defender role for its share market that saves from attacks from its competitors like as DISH (Dish Network Sling TV), SNE (Sony’s Playstation Vue), and GOOGLE (Alphabet’s Youtube Red) etc.
- Netflix provides a unique video quality approach as compared to other media service providers.
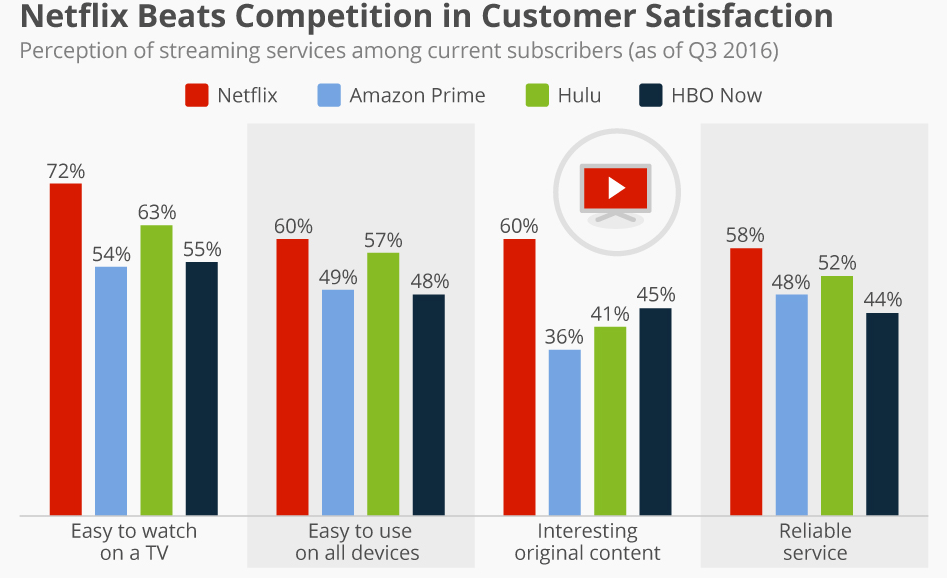
- Netflix beats its competitors in customer satisfaction. According to FORRESTOR survey in the USA, Netflix scored well as compared to its competitors related to the business point of view.
Conclusion
I hope you would love this information about Netflix infrastructure. In the 21st century, it has become a big brand for its creative feature, highly accessible data, and smooth look. Netflix has a solid production house and if you don’t have so much good production, none of the predictive analytics can save a TV show or series etc. In conclusion, every analysis does not give you the good result. Practically, analytics can not predict the success rate. But, it always helps in making the informed business decisions.
I excel when it comes to making bespoke data dashboards and visualizations that users and clients absolutely love. Sharing about things I enjoy doing is my hobby, whether it's about a project, collaboration, feedback, or just simple how-to guides about visualization.
If you have something to ask or share, I'd love to hear from you!
- Business Intelligence Vs Data Analytics: What’s the Difference? - December 10, 2020
- Effective Ways Data Analytics Helps Improve Business Growth - July 28, 2020
- How the Automotive Industry is Benefitting From Web Scraping - July 23, 2020