
In this blog, we’ll look at how to make improvements in MongoDB with Aggregation, Array and Topologies. With MongoDB 3.6 out, and us having discussed security, exchanges, and sessions, we would now be able to begin to discuss something substantially more fun.
This blog is based on the upgrades of clusters, dates and conglomerations. My objective here is basically divided into two sections: first to state what these are, and afterward likewise give a circumstance where it may be helpful. Similarly, as with most things, you ought to think about setting before using these features.
db.adminCommand( { setFeatureCompatibilityVersion: "3.6" } )
Initial, a notice: on the off chance that you do this and utilize a few highlights, downgrading back to 3.4 is a torment. In that capacity just utilize these highlights, sessions or security once you know your upgrade was steady.
So the choices in no specific request are:
- Diagnostic
- $currentOp
- $listSessions
- $listLocalSessions
- Arrays
- $arrayToObject
- $objectToArray
- $mergeObjects
- Date
- $dateFromString
- $dateFromParts
- $dateToParts
- General
- db.aggregate helper compared to db.collection.aggregate
- $hint
- $comment
- $$REMOVE inside conditional projection
- Non-Aggregation Arrays
- arrayFilters
- multi-element Array Updates
- push’s $position can use negative values
There’s a great deal there, yet don’t stress! The huge ones are the Non-Aggregation Arrays, $hint, Date and Array. Percona is here to help and I will go further into every region of these progressions by giving you a few cases.
Jump to Section
$hint is the act of informing the optimizer to use a specific index pattern
MongoDB moves increasingly into totals as the default inquiry framework for most rich actions (yet not point inquiries), it ends up noticeably basic.
The next logical step is allowing $hint, which is the demonstration of educating the enhancer to utilize a particular record example to solve the query. You may ask, “Shouldn’t it simply be settled on the correct choice?”
Well yes, yet all databases require this sort of usefulness in light of the fact that, depending upon the query pattern that gets reserved. It may have chosen one query regardless of whether a query of a similar example would profit more from another. If it’s not too much trouble note $graphLookup and $lookup are not ready to utilize $hint.
Envision you have a query from a given user searching for orders between two dates for a given classification like “PCs.” Logically, the file may be on classification and user, at that point from those outcomes, you shift through in view of the date. Consider the possibility that I revealed to you a few users were affiliates and Walmart was one of those” users.
All things considered, classification and date took after finally by the user would be significantly more effective.
A list’s activity is to sift through however much information as could reasonably be expected to diminish the calculation for any channel, not in the file. In this illustration, Walmart would have signed a bigger number of items in different requests than it would in PCs. Indeed, even within that information, it would help diminish a large number of conceivable records.
New Date Functions Inside MongoDB 3.6
There are three principle new date works within MongoDB 3.6: $dateFromString, $dateFromParts and $dateToParts. Be that as it may, what do these mean? We should investigate what is “parts” versus “string.” A part is a gathering of commonplace time fields. Truth be told, it included huge numbers of the average fields:
- year
- month
- day
- hour
- minute
- second
- milliseconds
- timezone
Looking at the situation objectively, these are conceivable parts a string could have when we are preparing for a string rather than parts. So these capacities are intended to help construct an ISODate protest from either an unpredictable record of the parts or a parsing of string date designs you may use in other code places.
For instance, datetime.strptime in Python or strtotime in PHP. This covers the $dateFromXXXX choices. In any case, in some code bases, you don’t generally need this Date question in MongoDB to should be marshaled by your application to have the capacity to develop an interior date to your code.
If you don’t mind take note of that numerous drivers will do this for you naturally, however, perhaps it could be a costly operation. You need to be more exact. All things considered, you can utilize $dateToParts, where it would enjoy a date and reprieve it into parts to be straightforwardly utilized by your application.
Another case of this is the capacity to have conditionals, where something must be consistent with executing. For this situation, having $dateToParts is more productive than a huge number of calls to all the part functions ($year, $minute, $week, $year, et cetera).
Array in MongoDB 3.6

A portion of the new array functions include $arrayToObject, $objectToArray and $ObjectMerge. I know the last one is a touch of an exception, yet this was sensibly the best place to keep it, as items are totally not at all like arrays outwardly.
$arrayToObject is my minimum top choice, as it has some exceptionally restricted conduct that will probably expect you to design your mapping, or if nothing else have another projection pipeline to set up your array information for what you require.
Some essential standards apply around this capacity. It anticipates that you will pass a variety of either two component exhibits or archives, where the estimation of the main thing is the “key” in the yield protest and the second esteem is the “esteem” in that yielded record.
In the event that that prep was not sufficiently terrible, we should likewise consider on the off chance that you have a “key” thing twice. The yield estimation of the thing field in the subsequent protest will be the incentive for the first array section to have coordinated it, not the last. I am not saying this is great or awful, as somebody needed to make an approach what was FIFO or FILO in the general conduct when copies are found.
On the off chance that you are befuddled, MongoDB has an extraordinary case in the manual here. The thought is that you have a stock framework with a stock field as a subdocument, where you have {warehouseName:currentStockValue} as fields and qualities.
Accepting this, they at that point utilize $concatArrays (think exhibit blend), so they can extend an “aggregate” section and incentive into this array, which brings about memory to an exhibit like [“warehouse1″=>13,”warehouse2″=>20,”total”=>33].
This, when connected to $arrayToObject, progresses toward becoming {warehouse1:13,warehouse2:20,total:33}. This is likely less demanding to work within your code, as it would be a local question or structure contingent upon the dialect included.
The following one is $objectToArray, which as you may figure is the correct inverse of above. You may have something like:

This becomes:

The last thing is $mergeObjects, which does what you expect: it consolidates objects. This would fill in as you would plan to join non-copy keys into a solitary ace protest yield. Where things are somewhat odd is at $ArrayToObject.
You may review me expressing the FIRST esteem is what is yield. In $mergeObjects, the LAST esteem wins. All things considered, please make an effort to remain exceptionally watchful when utilizing these that you recollect the request for utilization.
As a MongoDB user, I wish it was more steady, however, there are great purposes behind the conduct contrasts between what you need to expect with arrays versus objects.
Non-Aggregation Arrays in MongoDB 3.6
To begin, how about we discuss the huge one: arrayFilters. We are nearly discussing a subquery truly. In numerous refresh capacities, the discretionary arrayFilters field takes an exceptionally expressive array into it.
To keep things basic, suppose you have an application getting temperatures with an indoor regulator. How about we additionally accept on the off chance that its blunders, the temp is set to 212℉, which clearly would execute somebody. Because of this esteem, it totally diverts from the dashboards for your users.
How you manage this is a business choice, however for my situation, I chose I needed to set them to invalid as the diagram library would essentially skirt that plot point. Later focuses would help normal the line out, anticipating bizarre spikes or drops.
Presently, how about we additionally expect that I keep 24 focuses in an exhibit for every day to decrease the quantity to aggregate archives in the framework. In the event that I essentially dropped the information at one point, I would just have 23, and the reaches on my hub in the chart would change, so that is a no go. We have to stamp the incentive as invalid to counteract odd different practices.
So what would we be able to do? Before 3.6, I expected to pull the reports down to my content/application to settle the variety of components, and after that refresh the archive settling the issue. Clearly, this is not as much as perfect for some reasons yet required. Presently with 3.6, we have a greatly improved choice. What orders can be utilized to apply this new way?
- findAndModify
- findOneAndUpdate()
- findAndModify()
- update
- updateOne()
- updateMany()
- update()
- bulkWrite
- bulkWrite – updateOne or updateMany types
- bulk.find.arrayFilters() for Bulk supporting only updateOne()
In my case, I will simply utilize a refresh charge (what individuals typically would use for this sort of thing). So returning to our case, we should recap:
- Need to change any estimation of 212 to be invalid
- Must not erase a section as it causes issues for the application
- Must not have to pull all information to app to be sent back to database
You may be astounded at how basic this is present. I simply need to run the following:

I have kept this case straightforward, however, you could have significantly more rationale in the arrayFilters, where you may utilize $and permit conditions where on a business framework you need to apply a 25% markdown if something has more than 1000 duplicates in stock and has not gone at a bargain in a half year.
Taken after by another refresh, utilizing $or to expel anything from being on special that has been on special over the most recent a half year OR has under 1000 duplicates in stock. At any rate, doubtlessly you can perceive how much better this makes a large number of errands when you’re utilizing exhibits intensely in your plan.
The last point is around $position on a push charge. It used to be in the event that I needed to push to the finish of an array, I had to know its length to push to the end, or I could push to the begin of the exhibit. There are numerous situations where you need to affix versus prepend the new thing in an array.
Be that as it may, expecting to complete a read initially was an additional demand and furthermore opened you up to odd planning issues. Presently we can simply utilize – 1, as in most programming dialects, to do a similar thing. Be that as it may, we should note – 1 implies the component before the LAST one.
In the event that you need the component at the very end, you would need to utilize a misleadingly high number, as any number more noteworthy than the length will bring about pushing a component to the finish of the exhibit.
Diagnostic in MongoDB 3.6
This may be the most limited area of all, yet the objective of $currentOp, $listSessions, and $listSessionsLocal is to give more data by means of accumulations, in the moderate walk toward moving increasingly into that framework.
While these appear to be straightforward, there is some real power in them. In $currentOp, which must be the primary pipeline you have some extraordinary choices. The first is allUsers, which defaults to false and along these lines will just demonstrate your operations, not different people groups. The other is idleConnections, which are likewise off of course.
When it restores these qualities, you can utilize collection to $bucketAuto periods of inquiries. Or on the other hand possibly amass on getMore, replication, and general. Or on the other hand even utmost the response to particular shards or namespaces utilizing a $match. As should be obvious, it is capable!
Like currentOp, the session capacities can likewise utilize allUsers to list for all clients. They additionally have a clients alternative. In the clients alternative, you can pass an exhibit with the protest of {user: XXXX,db:XXXX} to channel the outcomes more.
Be that as it may, on the off chance that you are not utilizing validation, it will dependably restore all sessions. Likewise, with all charge conglomerations, it ought to likewise be in the main opening. The critical contrast is $listLocalSessions implies the session this hub has in memory, and $listSessions implies read the sessions from the system.sessions all the more specific.
General
As we have just examined $hint, I won’t cover it once more. In any case, there are some other general changes that are fascinating (however not what I would call major). The first is you would now be able to utilize db.aggregate() by passing it the namespace, and you don’t need to utilize db.collection.aggregate(). This isn’t a colossal change, yet it allows you to utilize the DB level extension.
$comment is another general change. On the off chance that you are from the RDBMS world, you will know frameworks like MySQL bolster remarks. The genuine power is it enables you to know when you have a moderate question what part of the subsystem did the demand originate from. This, thusly, makes support and operations groups significantly more proficient at investigating and settling an issue. If it’s not too much trouble use with alert, as remarks blended with huge collections could, in principle, surpass 16MB on the demand estimate.
This ought to be VERY uncommon, however, could even now affect truncation in logs and system.profiler. All things considered, be as short yet as particular as conceivable with any remarks. For instance, {$comment:”API::UserReq::addPrd(add_prod.py:23)”} would reveal to you the code way utilized and the document/line where this was called.
The last thing to cover is about $$REMOVE in $project conditionals. This is enormously intense, as should be obvious from a few yields on the off chance that you need to incorporate or conceal some field from your yield. The best clarification is found in the manual here, yet I will give you a speedy case.

You could obviously likewise set this to $seller.markup as zero. In any case, that would not utilize this new functionality.
Ideally, this has presented you to in any event a portion of the critical How to make Improvements in MongoDB 3.6 with Aggregation and Array.
MongoDB Topologies
The topic of the best engineering for MongoDB will emerge in your conversations between developers and architects. In this blog, we needed to go over the fundamental sharded and unsharded plans, with their pros and cons.
We will first take a look at “Replica Sets” Replica sets are the most basic form of high availability (HA) in MongoDB, and the building obstructs for sharding. From that point, we will cover sharding approaches and if you have to go that route.
Replica Set

A copy set in MongoDB is a gathering of mongod forms that keep up similar informational collection. Replica sets give repetition and high availability and are the reason for all production deployments.
Short of sharding, this is the perfect method to run MongoDB. Things like high availability, failover and recovery wind up noticeably robotized with no action typically needed. In the event that you expect huge development or more than 200G of data, you should consider utilizing this in addition to sharding to reduce your mean time to recuperation on a restore from backup.
Pros:
- Decisions happen automatically and unnoticed by application setup with a retry.
- Rebuilding a new node, or including an extra read-only hub, is as simple as “rs.add(‘hostname’)”.
- Can skip building indexes to enhance compose speed.
- Can have members
- hidden in another geographic area
- postponed replication
- investigation nodes through taggings
Cons:
- Depending upon the size of the oplog utilized, you can utilize 10-100+% more space to hold to change data for replication.
- You should scale up not out importance more costly hardware.
- Recovery utilizing a sharded approach is speedier than having is all on a single node (parallelism).
Flat Mongos (not load balanced)
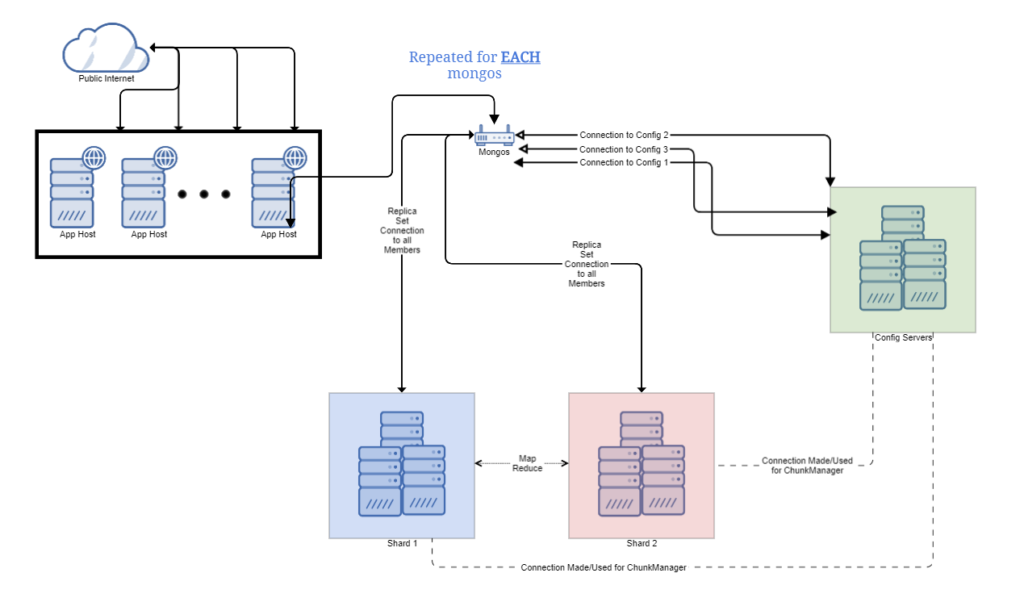
This is one of MongoDB’s more recommended deployment designs. To understand why we should discuss the driver and the fact that it supports a CSV list of mongos hosts for fail-over.
You can’t circulate writes in a single replica set. Instead, they all need to go to the essential node. You can appropriate reads to the secondaries utilizing Read Preferences. The driver monitors what is a primary and what is a secondary and routes queries appropriately.
Reasonably, the driver should have associations bucketed into the mongos they go to. This enabled the 3.0+ driver to be semi-stateless and ask any association with a particular mongos to preform a getMore to that mongos. In principle, this permits slightly more concurrency. Reasonably you just utilize one mongos, since this is only a fail-over system.
Pros:
- Mongos is alone apparatus, so it won’t run the application out of memory.
- If Mongos doesn’t react, the driver “fails-over” to the next in the list.
- Can be put nearer to the database or application relying upon your system and arranging needs.
Cons:
- You can’t use mongos in a list equally, so it is useful for fail-over (not evenness) in many drivers. If it’s not too much trouble read particular drivers for help, and test completely.
Load Balanced (preferred if possible)

You may likewise deploy a gathering of mongos instances and use a proxy/load balancer between the application and the mongos. In these deployments, you should configure the load balancer for customer affinity with the goal that each connection from a single customer achieves similar mongos.
This is the model utilized by platforms, for example, ObjectRocket. In this pattern, you move mongos nodes to their own tier but then put them behind a load-balancer.
Pros:
- Capacity to have an even utilization of mongos.
- Mongos are separated from each other and the applications to prevent memory and CPU conflict.
- You can undoubtedly expel or add mongos to help scale the layer without code changes.
- High availability at each level (various mongos, different configs, ReplSet for high availability and even numerous applications for application failures).
Cons:
- If batching is used, unless changed to an IP pinning algorithm (which loses equity) you can get “Cursor Not Found” errors because of the wrong mongos getting getMore and bulk connector connections.
App-Centric Mongos

By and large, this is one amongst the most typical deployment designs for MongoDB sharding. In it, we have every application host talking to a mongos on the local network interface. This guarantees there is next to no inactivity to the application from the mongos.
Pros:
- Local mongos on the loopback interface mean low to no dormancy.
- The limited extent of blackout if this mongos comes up short.
- Can be geologically more distant from the data storage in situations where you have a DR site.
Cons:
- Mongos being a memory hog can be taken from your application memory to help running it here.
- Being single-threaded, Mongos could turn into a bottleneck for your application.
- It is feasible for an ease network to cause bad decision making, including copy databases on various shards. The practical outcome is data writing intermittently to two areas, and a DBA must remediate that sooner or later (think MMM VIP ping pong issues).
- All arranging and points of confinement are connected on the application host. In situations where the sort uses an index, this is OK, however in the event that not filed the whole outcome set must be held in memory by mongos and then sorted, then returned the limited number of results to the customer.
Concluding Words
The topologies are above cover a large number of the arrangement requirements for MongoDB environments…
- Difference Between SQL and MySQL - April 14, 2020
- How to work with Subquery in Data Mining - March 23, 2018
- How to use browser features of Javascript? - March 9, 2018
Good and nice article