Jump to Section
What is Apache Spark
Apache Spark is a distributed and computing data processing framework for big data analytics. It can solve issues pertaining to millions of data in a quick manner. Apache Spark also provides fast and cluster computation environment. It is mainly based on MapReduce model, which supports types of computation like speed processing, stream processing. It automatically understands the compatibility of the exported data and processes them with large speed.
Why Apache Spark?
Apache Spark is an open source environment that reduces the high workloads in a less time as compared to big data Hadoop framework. It has inbuilt feature “in-memory” which increases the data processing speed to maintain a wide range of corporate workload like Iterative algorithms, batch processing, and interactive queries, etc. It also provides the variety of data sets in text format, graphical representations, and real-time stream data. Spark can work like a computing framework or stand-alone servers like Mesos and Yet Another Resource Negotiator (YARN).
Spark has a functionality to maximize the Hadoop cluster speed up to 50 times more faster in memory management and 10 times faster on running disk. Apache Spark works with Apache SQL queries, Machine Learning, Graphical Data Processing. As a result, A developer can easily use these entities to execute a single data structure for test cases. Apache Spark supports different languages like Python, Java or Scala.
Features of Apache Spark
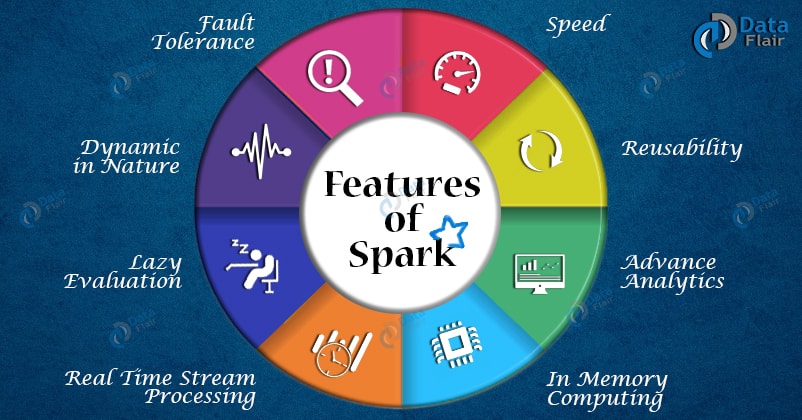
- Apache spark provides higher level APIs to maintain developer’s productivity and consistent data processing for big data. It has compatibility feature “in-memory” to maximize the speed for data processing, data storage, and real-time processing.
- It is fast in task performance as compared to another big data tools and it supports various functions except for Map and Reduces function. As a result, Apache Spark can manage operator graphical representations and well designed in Scala programming language.
- It’s fully associated with Hadoop-Distributed-File-System (HDFS) and it supports iteration algorithms with leading solution in Hadoop ecosystem. Apache Spark has big community active around the world. Global leading companies like IBM and DataBricks are using this framework on a broad level.
How does Apache Spark work?
Apache Spark works on master/slave platform. You can use any programming language with Apache Spark and its architecture. If you look at the image below, there is a driver which connects to cluster manager as “Master”. This master manages all the workers who run executors. Both executors and the driver can run java process simultaneously. You can even run both of them together on a single platform.
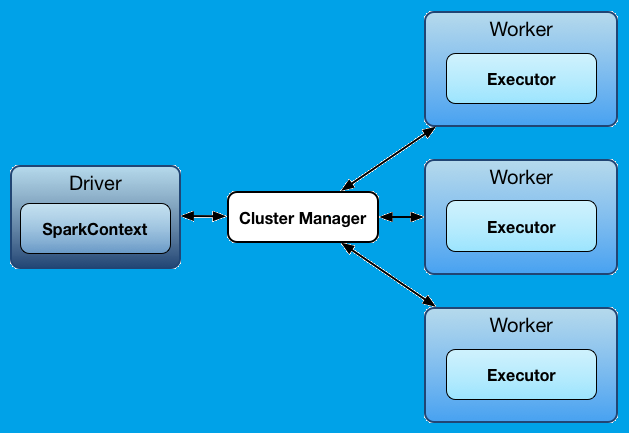
When an end-user submits a spark request to application code then the driver converts the code into the direct-acyclic-graph (DAG). Further, logical DAG transforms into the physical execution plan. This execution plan further divides into small execution. Now, the driver merges to the CM (Cluster manager) for resource environment. Then, cluster manager launches executor to send the task into small pieces. This is the rolling process of Apache Spark.
Spark Ecosystem Components
It has a huge ecosystem to store the data in a big storage. Spark ecosystem provides standard libraries with additional compatibilities in data analytics as follows.
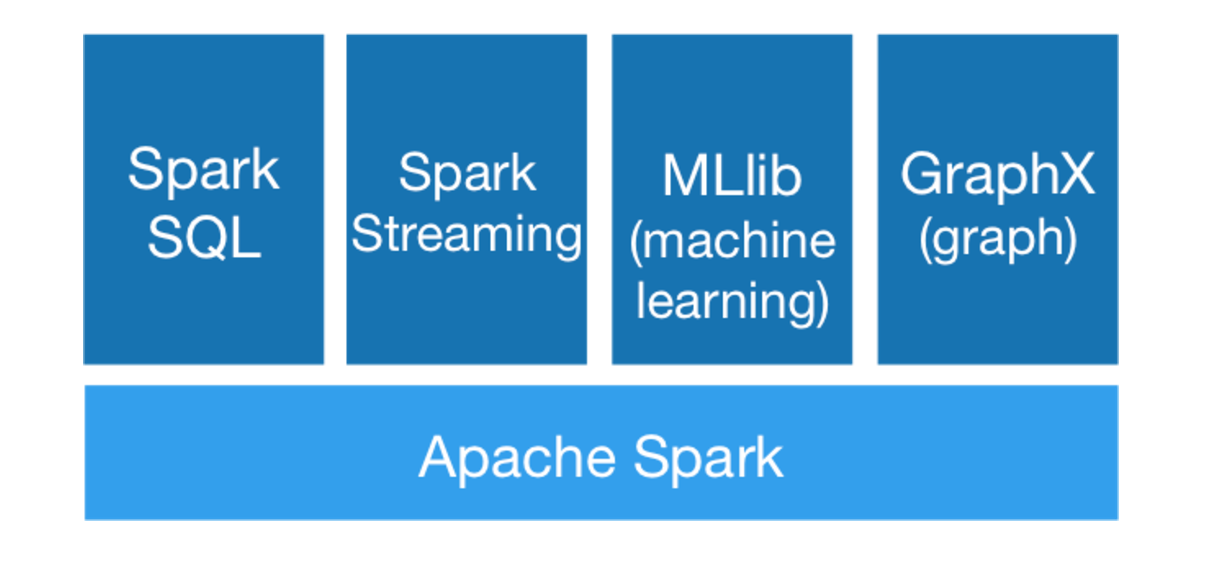
Spark SQL
It is a distributed framework for structured processing environment. Spark SQL explores the spark data sets over Java-Database-Connectivity (JDBC) APIs and allows commands to run traditional Business Intelligence and Visualization tools. Spark SQL provides solutions via Apache Hive Variant call as “HQL” that supports the source of data including Parquet, JSON and Hive Tables. It can perform additional computation and it does not need any API or language to explore the computation.
Spark SQL provides a new data solution as “SchemaRDD” which can access the semi-structured and structured information. It has amazing storage compatibility with Hive data. SQL and Data frames provide a common way to access resource environment.
Spark Streaming
It is a spark add-on core which is used for processing of analytics stream, fault-tolerant, and Throughput in live data streaming. Spark is completely accessible from the data sources like Kafka, Kinesis, TCP socket, and Flume. It also can operate various iterative algorithms.

Spark streaming can manipulate data streams of an API that define the combination of spark’s core RDD (Resilient Distributed Datasets) structure which helps developers to understand the project requirement easily. Apache spark streaming works on Micro-Batching (MC) for real-time streams and micro batching allows data handler to treat the live stream in small batches of data. Then, it delivers to the batches for further processing.
Apache Spark MLlib
MLlib is a highly integrated machine learning library that is accessible for both high-speed data and high data quality. MLlib provides different types of algorithms in machine learning including clustering, data import, regression, collaborative filtering, dimensionality, reduction, and classification. It also includes some lower level algorithm as generic gradient optimization.

These algorithms are only designed to scale across a cluster function. It is stored as “spark.mllib” in maintenance mode. It also uses a linear algebra package called as “Breeze”. Breeze is a combination of several libraries for numerical computation and machine learning.
Apache Spark GraphX
GraphX is the new distributed graph framework for graph processing, graph-parallel computation, and graph manipulation. Consequently, it works on multiple activities like classification, traversal, clustering, searching, and pathfinding. GraphX is an extended version of Spark RDD to make graphical representation like Spark SQL and Spark Streaming.
Conclusion
Apache Spark is the advanced and most popular product of Spark community that explores the structured live stream data. Spark has a solid ecosystem component like Spark SQL and Spark Streaming. These components are very famous as compared to different data frameworks. Apache defines the different type of data processing. By using this framework, you can segregate millions of data in different output like digital format, graphical and chart formats.
The whole concept of Apache Spark is established in Scala language. Apache provides a lazy evaluation data solution of big data analytics queries. In this article, I explained the basics of Apache Spark and its related components. It is purely a data analytics tool for those who want to make their career in Database and Data Science.
Thank you!
I excel when it comes to making bespoke data dashboards and visualizations that users and clients absolutely love. Sharing about things I enjoy doing is my hobby, whether it's about a project, collaboration, feedback, or just simple how-to guides about visualization.
If you have something to ask or share, I'd love to hear from you!
- Business Intelligence Vs Data Analytics: What’s the Difference? - December 10, 2020
- Effective Ways Data Analytics Helps Improve Business Growth - July 28, 2020
- How the Automotive Industry is Benefitting From Web Scraping - July 23, 2020