
Nowadays, we have huge amounts of data to store. But, it is not possible to store everything at the same place or on the same network. In other words, we can say that it is not possible to store all data in a centralized manner.
Naturally, the obvious question arises.
What is the solution for this?
To handle this situation, we have a technique that is known as a Distributed database system. We are using data that is remotely stored in different locations or on a different network. The goal is to use data in a cost-effective manner.
In this post, we are going to understand:
- What is the distributed database system?
- How to work with the distributed database system or we can say with distributed data?
- How can we use data replication MySQL?
Without further ado, let’s move forward. Firstly we need to know what is distributed database system.
Jump to Section
Distributed Database System
A distributed database is a collection of multiple interconnected databases and spread physically across various locations. All the interconnected databases communicate with each other over a network. A distributed Database management system manages the distributed database in a manner so that it looks like one single database to users. It is not a loosely connected file system.

The main goal of the distributed database is to maximize the performance by distributing data on different networks or locations. It also helps to utilize IT resources in a cost-effective, reliable, and in transparent manner. It ensures fault tolerance also. This database system enables resource accessibility when any other components fail. This will happen with the help of data replication.
Before this concept “distributed database”, data stored in one place that approach known as a centralized database. Firstly, We need to understand centralize database to know the features or the advantages of the distributed database over the centralized database.
Let’s see a comparison between the centralized database and the distributed database.
Centralized vs Distributed database
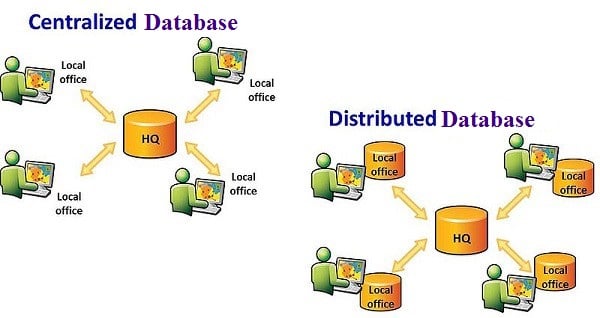
In a centralized database, all the data of an organization is stored in a single place. It can be on a mainframe computer or on a server. A Wide Area Network is used by the users who remotely access data. The centralized database should be able to satisfy all the requests coming to the system. Therefore, it is easy for it to become a bottleneck. It is easier to maintain and back up data because of all the data stored in one place. Because of data stored in a centralized database, outdated data is no longer available in other places. So in this way, it makes it easy to maintain data integrity.
In a distributed database, the data stored in storage devices that are located in different physical locations or in different geographical locations. They are not attached to a common CPU but the database is controlled by a central DBMS. To access data from the distributed database. The replication and duplication processes used to make the database up-to-date. Designing and maintain a distributed database is a more complex task rather than maintaining a centralized database.
Now the question is:
Why We Need Distributing Database System and What Are Its Features?
We need to access data that is stored on a different physical place or on a different network. It is not possible to store whole data on a single network. With the help of the distributed database system, we can able to store and retrieve the data from a different location or different network. Distributed database systems have different advantages that increasing the popularity of them.
So, the answer to the first question is:
Reasons/Needs of This System
- Distributed Nature of Organizational Units,
- Need for Sharing of Data,
- Support for Both OLTP and OLAP (OLTP stands for Online Transaction Processing and OLAP stands for Online Analytical Processing),
- Database Recovery,
- Support for Multiple Application Software.
Now it’s the turn of the second question’s answer.
Features of DDBS
Let’s talk about some of the features of this system…
- Reliability: Diversity of data reduces data loss. If the failure or data loss occurs on one site then the data on the other site does not have any impact or loss.
- Security: By giving permission to a single unit or section of the overall database. It provides internal and external protection of the data.
- Cost-effective: It reduces the bandwidth prices because users are accessing remote data.
- Local access: If the failure occurs in the umbrella network still you can access the portion of your data.
- Easy Integration: It is easy to create or add an additional node to the database. This integration makes distribution highly scalable.
- Speed & resource efficiency: It reduces remote traffic.
It is important that the distributed database remain up-to-date because of its distribution. The consistency should be there when the users use data that is remotely stored.
But the question arises that is it possible? If yes then how is it possible?
The Process to Maintain Consistency
Here is the answer to these questions. We have some process that remains database up-to-date. Those processes are as follows:
- Replication
- Duplication

Some specialized software used in the Replication process. This software observes all the changes/ modifications in the distributive database. Once that software identifies changes, the replication process makes all the databases look the same. The replication process can be complex. The Complexity of this process depends on the size and number of the distributed databases.
on the other hand…

Duplication has less complexity. A master database identified in this process and then duplicates that database. This duplication process takes place after an hour on a set time. In this process, Users can only able to change the master database. It ensures that local data will not be overwritten.
So, after the understanding of data replication and data duplication, it’s time to know about the type of distributed database.
The distributed database has its different Types.
Types of Distributed Database
A database user accesses the distributed database through two types of applications that are as follows:
-
- Local Applications
Local Applications do not require data from other sites.
-
- Global Applications
Global Applications require data from other sites.
There are two types of distributed database architecture:
- Homogeneous Distributed Database
- Heterogeneous Distributed Database
- Client/Server Database Architecture
Homogeneous Distributed Database
A homogeneous distributed database uses the same software and hardware on all the database sites. It appears a single interface as if it were a single database. So it is easy to design and manage this system. There are some conditions that must be satisfied by the system. Those conditions are as follows, the:
- Operating system of each location must be the same or compatible.
- Data structures of each location must be the same or compatible.
- Database application for each location must be the same or compatible.

The homogeneous distributed database further divided into two categories that are as follows:
- Autonomous: Each database has its own independent functions. All are integrated by a controlling application. It uses message passing to share data updates.
- Non-autonomous: Data distributed across the homogeneous sites. A central or master DBMS co-ordinates data updates across the different sites.
Heterogeneous Distributed Database
A heterogeneous distributed database uses different operating systems, hardware, database management systems on all the sites. In this system, different sites may use different schemas and different software. The different schema is a major problem for transaction processing and query processing.
For example
One location is using the latest database of relational DB, while another location using conventional files/ old version of the database to store the data. Similarly, the UNIX operating system used on one location, while another may be using Windows operating system.

In this system, the translation required to allow communication between different sites. The heterogeneous system is not a technically or economically feasible database. In this system, a user at one location able to read the data of the other location but not update the data of that site/location.
The heterogeneous distributed database further divided into two categories that are as follows:
- Federated: The heterogeneous database systems are independent in nature. It integrated together so that they provide the functionality as a single database system.
- Un-federated: The database systems have a central coordinating module through which the databases accessed.
Client/Server Database Architecture
Implementation of a distributed database system should be carefully managed within a client-server architecture. The server provides the resources for the client to use. The client receives the request from the user. This request is passed to the server by the client. The server receives, schedules, and executes the requests sent by the client. The request is sent to the server only when the client requests it.
All the computers connect with each other over a network. Each computer in a network is known as a node. So, that node can host one or more databases. Each node in a distributed database system can act as a client, a server, or sometimes both. It all depends on the situation.

So, now let’s talk about the Distributed database architecture using MySQL replication.
Distributed Database Architecture Using Mysql Replication
A distributed database system allows applications to access data from the local and from the remote databases. We use a client/server architecture to process information requests in a Distributed databases of MySQL replication.
The word replication stands for the operation of copying data and maintaining database objects. These objects belonging to a distributed database system.
The architecture is based on a series of delivery servers that reports back to a central database. The server can be scaled by adding more delivery servers.
This architecture provides good redundancy. So that any failure on a single server will not disable the whole system. A load balancer takes place here. This load balancer will handle a delivery server outage by distributing the extra load across the other delivery servers. This architecture will eliminate most single points of failure, and allows unlimited scalability almost.
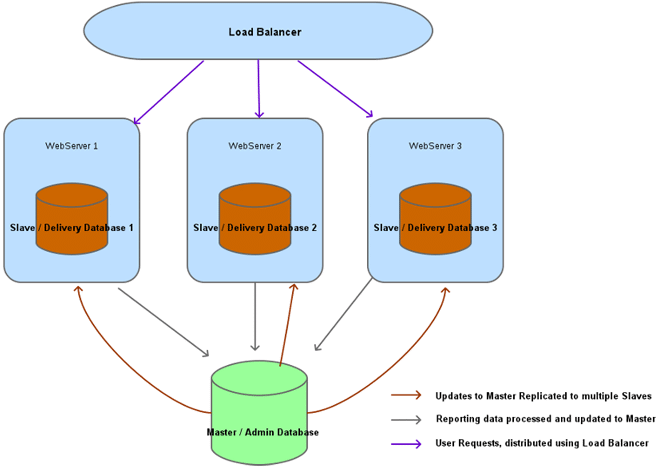
We can balance the writes across the web servers With the Distributed Database Architecture.
Also to have full High Availability and Redundancy we can use a Master-Master replication at the Admin/Central Database.
Steps For MySQL Replication
Below are the steps for MySQL replication.
Replication Documentation
You can refer to this link for further understanding of the MySQL replication process because it is not possible to make all the things understandable in a brief part.
http://dev.mysql.com/doc/refman/5.5/en/replication.html

 Advantages of Replication in MySQL
Advantages of Replication in MySQL
 Advantages of Replication in MySQL
Advantages of Replication in MySQLAdvantages of replication in MySQL are as follows:
- Scale-out solutions,
- Data security,
- Analytics,
- Long-distance data distribution.
This is a brief introductory part of the distributed database system and its architecture. So now it is the time to conclude it.
Conclusion
The distributed database system makes work easier in every field especially it fulfills the business needs. Hence, it changes the way of data access and reduces the network loads by the distribution of the data. So, we are free to store and retrieve data from different networks or locations.
This concept of the distributed data system makes cloud computing a worthy technology. Without the data distribution, cloud computing is nothing.
Hence, this system has more advantages over the centralized database system. So, I think it gives some basic understanding of a distributed database system and its architecture.
I excel when it comes to making bespoke data dashboards and visualizations that users and clients absolutely love. Sharing about things I enjoy doing is my hobby, whether it's about a project, collaboration, feedback, or just simple how-to guides about visualization.
If you have something to ask or share, I'd love to hear from you!
- Business Intelligence Vs Data Analytics: What’s the Difference? - December 10, 2020
- Effective Ways Data Analytics Helps Improve Business Growth - July 28, 2020
- How the Automotive Industry is Benefitting From Web Scraping - July 23, 2020