
An outlier is an abnormal value in the collective data that is gathered for a purpose. It is that value which lies at an abnormal distance from the rest of the others in a random sample. When the data are obtained for a particular sample, it is expected to be in a particular range. In other words, most of the data in a sample follows a particular trend. However, some turn abrupt. These abrupt data that stand out from the rest are outliers.
It is entirely up to the analyst to understand and distinguish between the data that makes sense, and one that is distanced from the others. Outliers can have an immense influence on the overall data. These can be in the form of statistical influences such as means, standard deviations, co-relations etc. Or in the form of interpretation of the data through tools such as linear regression, ANOVA etc. Whatever, the impact may be, outliers can mess up your critical analysis and pose challenges in your research.
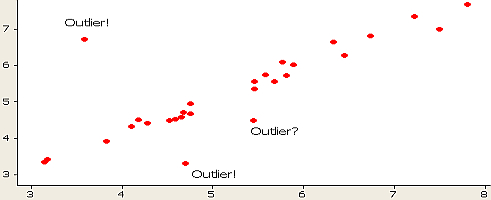
Outliers are the most enduring and ubiquitous forms of methodological challenge in research and analysis of the data. Most of the people know that outliers exist, but don’t know what to do with them. Or in other cases, most of the people use inadequate measures that not just affects the statistical outcomes but also analysis to a severe extent. It is also a matter of observation that analysts often drop outliers from their data, which is a generic step towards getting accurate results. However, this does not guarantee quintessential results.
By being distinct from their groups, such as individuals, groups or firms, outliers pose a great concern to organisations due to their power of altering conclusions. Right from the micro level to macro level organisations, outliers are the biggest concern on research and analysis these days.
Here are a few ways to Tackle Inadequate Handling of Outliers
Setting up a filter in the testing tool
One of the most effective ways of tackling outliers is setting up a filter in your testing tool. It may seem like a costly move towards collecting data, but is also smart. Filtering out outliers facilitates not risking the proper data to any abnormalities. In this way, you’re keeping your analytical results safe from abrupt conclusions. Without filtering out outliers, you can witness significant impact on the data that will always lead to ambiguity in your research and analysis.
As businesses look forward to increasing their revenue, filtering outliers can be a smart move. It is always advised to take a look at the past data and trend of outcomes to understand an average for your organisational research. For example, take a trend of order values for your company over a significant period. If the average orders for the oat three months are $100 and you spot a value going above $200 in your current data, consider this as an outlier. Furthermore, to maintain the accuracy and transparency of your results, filters accomplish the task of removing these outliers.
Cap the data
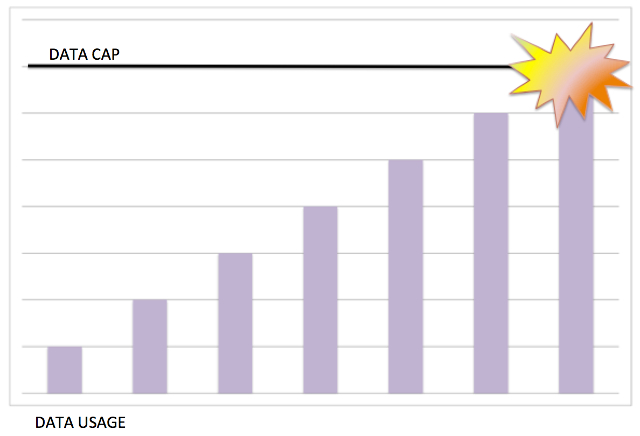
Another useful tactic for handling outliers is capping the set of data. Capping is setting limits to your collected data. It helps in accessing the range of data as per the requirements of the research. For example, if you’re analysing the group of different income buyers in your business, you can get a picture that a certain level of income group has peculiar buying trends while others have different. Some may perform a transaction for more necessities while others for luxuries. Capping your data to the relevant study can help you get rid of outliers. Moreover, the outliers, if any in your analysis, would lie outside your model study group. And no abrupt values mean more accurate and precise results.
Calculate before and after results
Even the presence of a single outlier can cause your conclusion and statistical models to fluctuate rapidly. While people often prefer to drop outliers, it is not an appropriate measure in most of the situations. A smart and effective strategy can be to calculate the before and after results of an outlier.
The first step is to draw your conclusions such as statistical analysis in the presence of an outlier. Undoubtedly, the outliers will affect your results. This process is just done to take a reference of the abruptness or variation from the true result.
In the next step, remove the outliers entirely from your data and adopt a statistical or another relevant approach for analysis. This step is similar to the practice where analysts drop for the outliers from their studies and draw their entire results based on it.
This analysis will draw important conclusions based on the first part of calculating results with an outlier and the second part where the outliers were eliminated from the results. Surely, you will find a tremendous difference in both the results, which explains the effect of outliers in the study.
Algorithms and mathematical functions: Analysts also take the help of algorithms and mathematical functions to tackle inadequate handling of outliers in the analysis. It is one of the most appropriate yet time taking process. Popular methods include-
- Winsorization: This process includes transforming the extreme values to a particular percentile of the data. For example, transforming to a 90th percentile will enable the transformation of the data below the 5th percentile to it. Therefore, the data above the 95th percentile will, therefore, be set or capped at the 95th percentile.
- Univariate method: This machine earning methodology, finds the data point that has extreme values on one variable.
- Minkowski error: This method focuses on reducing the offering of potential outliers, right in the training process.
Outliers pose as one of the greatest challenges when analysing a predictive study of an organisation. They lead to poorer results and bad conclusions. To achieve potential success in arriving at predictive conclusions, it is therefore mandatory to tackle outliers in the study through appropriate measures and adequate practices.
I excel when it comes to making bespoke data dashboards and visualizations that users and clients absolutely love. Sharing about things I enjoy doing is my hobby, whether it's about a project, collaboration, feedback, or just simple how-to guides about visualization.
If you have something to ask or share, I'd love to hear from you!
- Business Intelligence Vs Data Analytics: What’s the Difference? - December 10, 2020
- Effective Ways Data Analytics Helps Improve Business Growth - July 28, 2020
- How the Automotive Industry is Benefitting From Web Scraping - July 23, 2020