
Previously, scraping was although a tough process with the use of DOM Elements. It was actually not a pleasure to work with this slow and boring process. But, thanks to the new and improved process of HTML Agility-Pack Library, which has actually made the whole process an easy one!
With features like easy to understand, fast pace working speed and exact data extraction, HTML Agility-Pack is ruling the world of Web Scraping. Sounds interesting? Then why not dwell more about it! Here, we go…
Jump to Section
What Is Agility-Pack?
Before moving ahead with the detailed version, let’s first start with the basics. Understanding the basic concept of HTML Agility-Pack can help you proceed ahead smoothly with the topic…
- This is an agile HTML parser that builds a read/write Document Object Model and supports plain X-PATH(XML Path) or XSLT(Extensible Style-sheet Language Transformations).
- It is a .NET code library that allows you to parse “out of the web” HTML files.
- The parser is very tolerant of “real world” malformed HTML.
- In Simple, you can scrape web pages present on the internet using this library.
How Does HTML Agility Pack Work?
Having a knowledge of the working process of a specific technology can help with its further better understanding, so why not give it a shot!
HTML Agility Pack is used to parse HTML documents. It is a free, open-source library designed to simplify reading from and writing to HTML documents. It constructs a Document Object Model view of the HTML document being parsed.
With a few lines of code, developers can walk through the Document Object Model, moving from a node to its children, or vice versa. Also, the HTML Agility Pack can return specific nodes in the DOM(Document Object Model) through the use of X-Path expressions.
What Is X-PATH?
X-Path is a special syntax used to navigate through elements and attributes in an XML document.in other words, X-Path is used to iterate and access any node within an XML document. Different functions and experiences are available within Z-Path specifications to help access different kind of XML nodes. HTML Agility pack uses X-Path to access any of node within an HTML document.
There are some expressions of X-path given as:-
- node-name : Selects all child nodes of the named node.
- / : Select from the Top(root) node.
- // : Select nodes in the document from the current node that match the selection no matter where nodes are.
- . : Select the current node.
- .. : Select the parent of the current node.
- @ : Select attributes.
We can find x-path by right click on the browser, go into inspect now select any tag to find x-path in inspect element window and again right click on this tag, go to copy and click on copy x-path then you find suitable x-path and correct it according to your need.
How To Use HTML Agility-Pack?
The Html Agility Pack is wrapped inside a single assembly, HtmlAgilityPack.dll. To use the Html Agility Pack you’ll need to copy this assembly into your project’s bin folder. With the Html Agility Pack assembly in the Bin folder, you’re ready to start downloading and parsing HTML documents.
Here’s how to use the Html Agility Pack to perform a parsing tasks as:-
Listing the Meta Tags on a Remote Web Page.
Listing the Meta Tags :-
- Screen scraping usually involves downloading the HTML for a specific web page and picking out particular pieces of information.
- This first shows how to use the Html Agility Pack to download a remote web page and enumerate the <meta> tags, displaying those <meta> tags that contain both a name and content attribute.
- The Html Agility Pack enclose a number of classes, all in the HtmlAgilityPack namespace. Therefore, start by adding a using statement to the top of your code-behind class.
As:-- using HtmlAgilityPack;
- To download a web page from a remote server, use the HtmlWeb class’s Load method, passing in the URL to download.
- var webGet = new HtmlWeb();
- var document = webGet.Load(url);
- The Load method returns an Html-document object. In the above code fragment, we’ve assigned this returned object to the local variable document. The Html-document class represents a complete HTML document and contains a Document-node property, which returns an Html-node object that represents the root node of the document.
- The HtmlNode class has several properties for traversing the DOM, including:-
- ParentNode,
- ChildNodes,
- NextSibling and
- PreviousSibling
- There are some properties for determining information about the node itself, as:-
- Name : Gets or sets the node’s name. For HTML elements name property returns (or assigns) the name of the tag – “body” for the <body> tag, “p” for a <p> tag, and so on.
- Attributes : It returns the collection of attributes for this element if any.
- InnerHtml : Gets or sets the HTML content within the node.
- InnerText : Returns the text within the node.
- NodeType : Indicates the type of the node. Can be Document, Element, Comment, or Text.
- There are also methods for fetching particular nodes relative to this one. For instance, the Ancestors method returns a collection of all ancestor nodes. And the SelectNodes method returns a collection of nodes that match a specified XPath expression.
- There are a variety of ways you could get a list of all <meta> tags in the HTML document. For this demo I decided to use the SelectNodes method. The statement below calls the SelectNodes method of the document object’s DocumentNode property, using the XPath expression “//meta”, which returns all of the tags in the document.
- var metaTags = document.DocumentNode.SelectNodes(“//meta”);
- If there are no tags in the document then, at this point, meta tags will be null. But if there are one or more tags then meta Tags will be a collection of matching Html Node objects. We can enumerate these matching nodes an display their attributes.
- The foreach loop itemize(enumerates) the items in metaTags (if it’s not null) and checks to see that there exists name and content attributes. Presuming these attributes exist, thetag information is emitted.
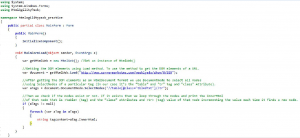
- if (metaTags != null)
{
foreach (var tag in metaTags)
{
if (tag.Attributes[“name”] != null && tag.Attributes[“content”] != null)
{
… output tag.Attributes[“name”].Value and tag.Attributes[“content”].Value …
}
}
}
- if (metaTags != null)
HTML Parser
It allows you to parse HTML and return an HtmlDocument. We can parse:-
- From File : Loads an HTML document from a file.
- From String : Loads the HTML document from the specified string.
- From Web : Gets an HTML document from an Internet resource.
Load Html From File
HtmlDocument.Load method loads an HTML document from a file.
- Example:- The following example loads Html from file.
- var path=@”test.html”;var doc=new HtmlDocument();doc.Load(path);var node=doc.DocumentNode.SelectSingleNode(“//body”);Console.WriteLine(node.OuterHtml);
Load Html From String
HtmlDocument.LoadHtml method loads the HTML document from the specified string.
- Example:- The following example loads an Html from the specified string.
- var html = @”<!DOCTYPE html>
<html>
<body>
<h1>This is <b>bold</b> heading</h1>
<p>This is <u>underlined</u> paragraph</p>
<h2>This is <i>italic</i> heading</h2>
</body>
</html> “;
var htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(html);
Var htmlBody = htmlDoc.DocumentNode.SelectSingleNode(“//body”);
Console.WriteLine(htmlBody.OuterHtml);
- var html = @”<!DOCTYPE html>
Load Html From Web
HtmlWeb.Load method gets HTML document from an web resource.
- Example:-The following example loads an Html from the web.
- var html = @”http://html-agility-pack.net/”;
HtmlWeb web = new HtmlWeb();
var htmlDoc = web.Load(html);
var node = htmlDoc.DocumentNode.SelectSingleNode(“//head/title”);
Console.WriteLine(“Node Name: “+ node.Name + “\n” +node.OuterHtml);
- var html = @”http://html-agility-pack.net/”;
This is all for this portion. The rest is definitely to be continued in the Part-2 of the article. For more technolgy related blogs visit https://www.loginworks.com/blogs/
I excel when it comes to making bespoke data dashboards and visualizations that users and clients absolutely love. Sharing about things I enjoy doing is my hobby, whether it's about a project, collaboration, feedback, or just simple how-to guides about visualization.
If you have something to ask or share, I'd love to hear from you!
- Business Intelligence Vs Data Analytics: What’s the Difference? - December 10, 2020
- Effective Ways Data Analytics Helps Improve Business Growth - July 28, 2020
- How the Automotive Industry is Benefitting From Web Scraping - July 23, 2020