
In my previous blog, I covered the basics of big data application and testing strategy that needs to be followed for a big data application. As a tester, we must have a little knowledge of basic technology on which our application is based. In this blog, we will have a technical walkthrough of the big data frameworks and its commonly used terms.
Technical knowledge enables us to identify critical loopholes in the application. In other words, a number of area of improvements and bugs we can find is dependent on how much technical knowledge we have.
Jump to Section
Frameworks available for big data application
Most of the big data applications are based on HADOOP framework, which is basically popular for distributed parallel processing of data. Hadoop is an open-source framework, which processes big data set in batch processing pattern with use of distributed storage. Apart from HADOOP, there are few other open source frameworks available in the market, these are:
- Apache Spark
- Apache Storm
- Flink
- Samza
Choice of data processing frameworks is based on the primary necessity of the business for which application is going to develop. Each framework has its own capabilities, for example, frameworks are not intended to be one-size-fits-all solutions for businesses.
HADOOP is designed for massive scalability, while Spark is better with machine learning and stream processing. A good IT services consultant can evaluate your needs and offer advice. What works for one business may not work for another, and to get the best possible results, you may find that it’s a good idea to use different frameworks for different parts of your data processing.
HADOOP for Big Data Application
There may be a question arise in your mind that if there are many other frameworks available then why only Hadoop is widely used in big data applications???
So, the answer to this question is, HADOOP was the first framework, which was originally designed for big data application to handle massive scalability. As it was designed many years back, so most of the running big data application is based on this framework.
Nowadays, the successor of HADOOP frameworks, i.e., Spark is getting popular for big data application. as it is the successor of HADOOP framework, it has a number of advantages over HADOOP for more information for Spark you can go through a site where you will get a thorough knowledge of all advanced feature of Spark over Hadoop. However, to understand Spark or any other framework, we must have knowledge of basic framework, which is HADOOP.
HADOOP: Basics
HADOOP is an open source framework, which is based on distributed and parallel processing. It uses HDFS (HADOOP Distributed File System), which stores data across multiple clusters of machines. it is capable to identify the machine failure and can handle them at the application level.
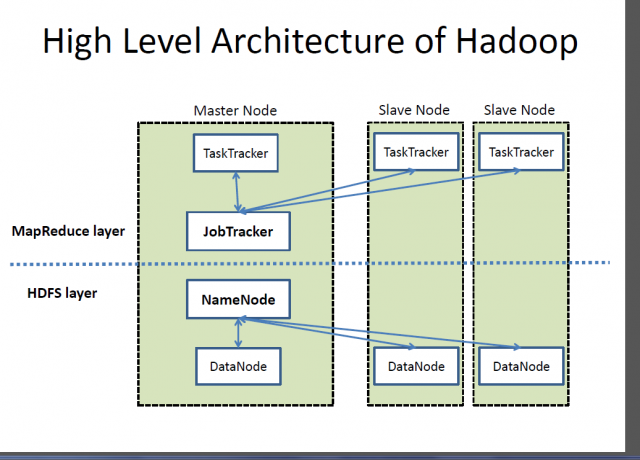
Hadoop basically consists of following components:
- Hadoop Common: It refers to all Utilities and libraries used by Hadoop module. It consists of Hive, Hive QL, Pig, Mahout and Oozie.
- Hadoop Distributed File System (HDFS): It refers to the distributed file system to store data. Hadoop Distributed File System is storage component of Hadoop.
- The Hadoop MapReduce involves the implementation of the MapReduce programming model for large-scale data processing.
Major Components of Hadoop

Hadoop operates a large amount of data by distributing it across different nodes in clusters. A cluster refers to a set of small machines, which process data in a parallel manner. Each machine in these clusters named as node, each node performs a specific task on the based on algorithm assigned to that node.
HADOOP keeps data in a redundant manner on different machines so there is no chance of data loss in case of any mechanical failure. HADOOP processes the data in separate JVMs. these JVM never share states. In HADOOP, there can be as many JVMs as required. Each cluster has its own JVM.
HADOOP can be implemented in two ways: Single machine and Fully distributed.
Fully distributed is referred as pseudo-distributed. Single Machine Hadoop consists of the regular file system and single JVM. Whereas, Pseudo distributed Hadoop uses HDFS (Hadoop Distributed File System) and more than one JVMs. Although these JVMs are in the single system they never share its status with each other. Each JVM performs a specific function and there are some integrator and aggregator for proper information processing.
Map Reduce
Map Reduce is one of the key components of HADOOP. It refers to the programming paradigm used in HADOOP that works on three major functions, i.e., Map, Shuffle and Reduce. There are two main functions Map and Reduce.
The map function is for assigning a task to different machines configured in Hadoop framework. Reduce function reduces the information in order to store it in Data warehouse for displaying it in different components such as Report, Dashlet and Charts. There is one more function named as Shuffle in between map and Reduce .Shuffle is for arranging the processed information on the basis of the business rule.

HDFS (Hadoop Distributed File System)
HDFS consists of three components: Name Node, Data Node, Secondary Name Node. Working of HDFS depends on Master-Slave architecture model. NameNode generally works as a master node and DataNode acts as a slave node. Node refers to a machine included in a cluster.
Namenode is a central directory, which keeps track of data in different machines in the storage cluster. Whenever there is need to locate a file in the file system, a client machine contacts to the Namenode. Namenode contains a list of all data nodes that can be used to locate the file.
Data node is generally used to store data and process it. There is one another node, i.e, Master Node. Master node takes care of all data storage and its processing. Data storage and job tracker for its processing is the main task of Namenode. Job tracker is responsible for assigned task on different machines and identifies machines failure.
A Hadoop cluster consists of the master node, client node, job tracker, name node, data node and worker node. Worker node refers to a group of virtual machines, which store and process data. Each worker node communicates with the master node by transferring messages to it with help of data node and task tracker.
Well, this was a technical walkthrough through the Big Data Framework and I hope it was quite a useful and informative one!
I excel when it comes to making bespoke data dashboards and visualizations that users and clients absolutely love. Sharing about things I enjoy doing is my hobby, whether it's about a project, collaboration, feedback, or just simple how-to guides about visualization.
If you have something to ask or share, I'd love to hear from you!
- Business Intelligence Vs Data Analytics: What’s the Difference? - December 10, 2020
- Effective Ways Data Analytics Helps Improve Business Growth - July 28, 2020
- How the Automotive Industry is Benefitting From Web Scraping - July 23, 2020