
Moving applications from one platform to another can be an urgent business need at times. It is also a nightmare for businesses and people struggling with Information technology platforms. When you plan to move an application, various complex processes run in the background. Now detaching those from one platform and shifting the entire process to another can be an extensive task that requires endless lines of coding. For this reason, businesses find this task exigent and stick to one platform, even after realizing that the other one might have huge potential for the application.
KIBA, on the other hand, is a lightweight ETL framework for Ruby. It eases the hefty task of data migration without having to spend huge loads of time or writing immense lines of code for a simple task. During the process of data migration, there is a lot of update and transformation required in the old system before it feeding into the new system. It is a complex process and instigates fear in the heart of business people responsible for the task. Even the simplest tasks of data migration can prove to be painful for an organization.
Jump to Section
Understanding KIBA
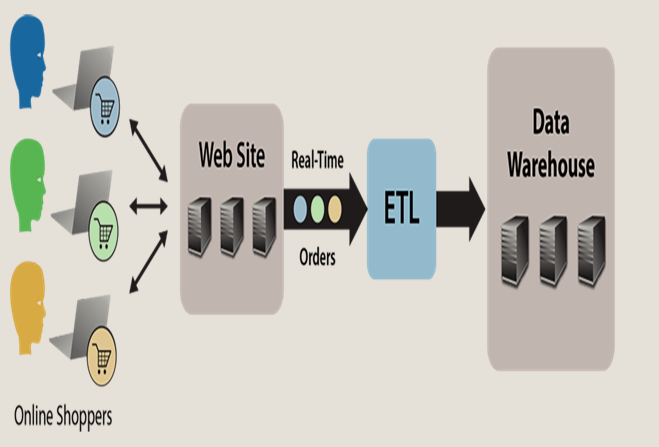
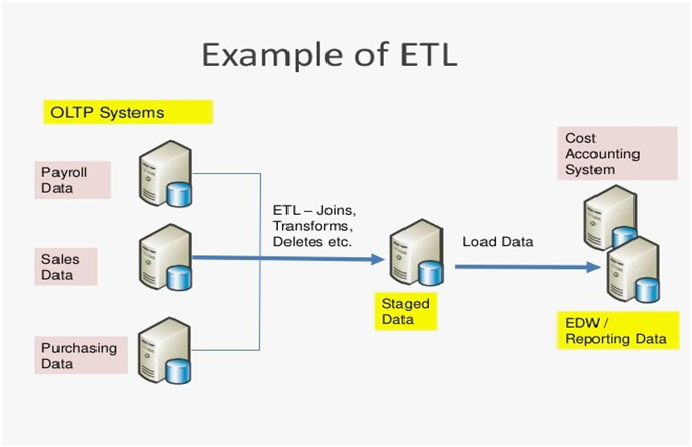
To begin with KIBA, a simple migration of application may include extracting data from one source, transforming or processing it and then storing it at a new location. As complex as it sounds even for a basic data migration task, with KIBA this task could never have been easier. You might have heard about Ruby on the Rails. KIBA is just another framework of Ruby that runs on the ETL cycle. For those who are unaware about ETL, it is the abbreviation of
- E- Extract: Extract refers to extracting data from the source system for further processing. It is the first step in the cycle.
- T- Transform: This is the second step of the ETL cycle. It is the part of the cycle where you apply functions as per the requirements to transform the data into a standard schema. This stage helps in preparing the data for the destination or delivery to the final migration platform.
- L- Load: The last part of the cycle is called load. It is where the data is loaded into the data mart and consumed. All the processing and transformation occurs in this part of the process. After the transformation takes place in the data mart, it is passed onto the cube and reaches the destination. Here it can be then used for browsing.
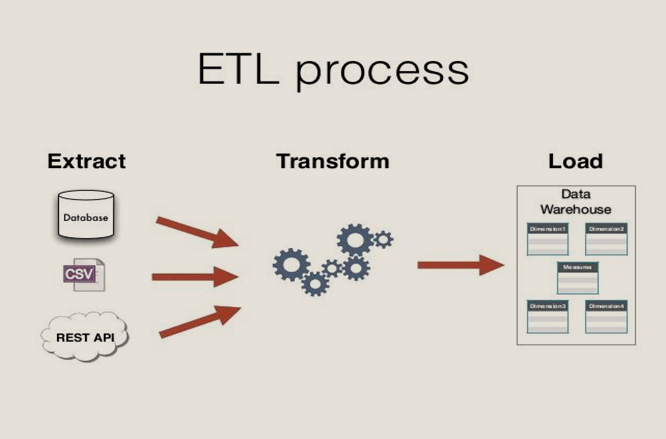
Just the way it sounds, ETL is a substituted word for data migration and the quintessential framework built under Ruby on the Rails for this task. When talking about ETL, you are sure about two things- the source from where you pull the data and the destination, where you deploy it. The transformation process in the middle ensures that the source data matches the desirable format to fit into the new platform. To begin with, the three steps to swear in the process of data migration include:
- Pulling the data from the source
- Changing it to match requirements
- Writing it into the new destination
KIBA aims at solving this issue and making the entire process hassle-free. Various skeptical approaches to ETL processing have proved that KIBA stands as a robust solution with its simplicity and flexibility. ThibautBarrereis the father of KIBA that has ever since its birth been used extensively by organizations for simplifying their data migration processes.
Attractive Features of KIBA
Take-away pipeline
Transformation on KIBA has unique and useful features that are not just for a one-time utility, but used again and again as per the requirements of data migration. Understand it analogous to a pipeline. KIBA has some transformation pipes that you can take anywhere of your choice. Moreover, these transformations can be taken anywhere and tested separately. This practice will bring a fully mature development cycle to your data processing ETL.
Pre-processors
KIBA offers some attractive features like the pre-processors in ETL cycle. Pre-processors are run just before the sources and accessed in the pipeline. It helps in defining the data processing lifecycle. In technical terms, a pre-processor is a block that you call before reading the first row of your source. Pre-processors handle any overall setup required in the ETL cycle.
Post-processors
KIBA also offers post processors in the ETL cycle. These are run in the program when there is a need to write all the rows to the destination. It also helps in defining the pipeline. In technical terms, you can call a post processor a block after you migrate all the rows in data migration. Post-processors handle any overall cleanup required in the process.
Storing ETL jobs
There are different ways in which you can store ETL jobs in KIBA. It mostly depends on how you call them.
- In one instance you may use the command line to store EYL definitions with an extension .etl
- In another instance, you can call your KIBA jobs through programming via tools such as Rake or Sidekiq etc. You can store your ETL definitions in .rb extension for this process.
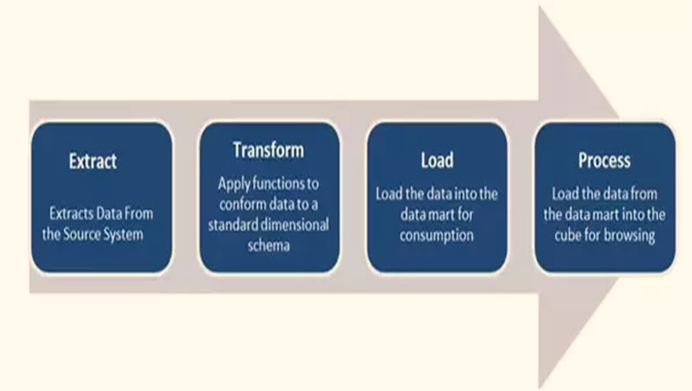
KIBA ETL Lifecycle
The ETL lifecycle in KIBA can be broken down for the simplification process and comprehensive understanding.
- A KIBA source is a special defined class that has a constructor specific to the source. For example, it could be a file name. It implements a keyword ‘each’ that yields rows to the block.
- To implement your source, you must create a Ruby class that specifically corresponds to ‘each’. It will help you yield all the rows one by one. This method includes one constructor and method.
- In the ETL declaration, you also need to pass the parameters of the class and constructor in KIBA. KIBA will automatically do the instantiation and creation of the source constructor.
- For example, if you want to read a CSV file source, KIBA will open the file by using headers to build a hash or hashes of data and close it at the end. In KIBA, you will be able to yield only one row per CSV file.
- Once you have your class, you can easily declare your source in the ETL KIBA script. After this, the arguments passed to the source by KIBA, and the source starts yielding one row after another to feed the ETL pipeline.
- The KIBA transform is just a class which corresponds to a process in the Ruby Rails. It simply receives the row at a definite stage of a pipeline, which you can modify as per the requirements. Once modified, you must return it to pass through the next stage of the pipeline. The syntax for returning is the same as passing. The process incorporates the use of the keyword ‘transform’ in the pipeline.
- The final stage of the ETL lifecycle is the destination. The destination in KIBA is a class which has a constructor similar to that of the source. It helps in the initialization of the destination in the ETL pipeline. It also takes on the responsibility to send the row to the target data destination store.
Two major methods in this class are:
- Write: It helps in writing the row to the destination.
- Close: It helps in cleaning up after itself. For example, closing a file or database connection.
Challenges
ETL with iteration
When there are large data sets involved, ETL gets slow. So in order to execute queries without any difficulty, the developers suggested the use of #start, #step, and #stop blocks to add iteration. This iteration will optimize the code block and ensure quick results.
ETL Dependencies
Ruby ETL has dependencies before it can query to all databases. ETL can make a connection if the object to #query. To fix this, a library is added to the code. Ruby’s Simple Delegator is added along with a #query method, in some cases.
ETL complexity
ETL gets complicated when there are multiple data sources. A complex environment which has to use data sources which are of type databases, flat files, excel docs and service logs, ETL can slow down the process. These complex scenarios are usually resorting to big data for a solution. All these dependencies and problems have led to the newer version of KIBA 2.0.
KIBA 2.0
The newer version of KIBA , introduced a new Streaming Runner engine. The opt-in engine is called the Streaming Runner. The engine allows to generate in-class transforms, an arbitrary number of rows. This engine can improve the reusability of the KIBA components. To the above-mentioned challenges, KIBA has come up with this reusable and reliable KIBA version.
Conclusion
Thus, the KIBA ETL processing offers a code-centric lifecycle. The facilitation of various tested components can further ease the task of data migration and processing in businesses. KIBA has been able to make its mark in the world of data processing because of its ease of use, powerful domain specific language or DSL. It has also filled the gap of the Ruby ETL ecosystem. With reusable and easy to maintain components, KIBA accounts for a widely used data enriching and transforming tool.
I excel when it comes to making bespoke data dashboards and visualizations that users and clients absolutely love. Sharing about things I enjoy doing is my hobby, whether it's about a project, collaboration, feedback, or just simple how-to guides about visualization.
If you have something to ask or share, I'd love to hear from you!
- Business Intelligence Vs Data Analytics: What’s the Difference? - December 10, 2020
- Effective Ways Data Analytics Helps Improve Business Growth - July 28, 2020
- How the Automotive Industry is Benefitting From Web Scraping - July 23, 2020