What exactly is data processing, and what is information processing? Where does each apply, and which should be used for what? Is one better than another? These are some of the questions I’m going to try to answer for you in this article.
To begin with, information processing and data processing are primarily two different aspects of data science. To put it simply, Data processing deals with extraction information from raw material; information processing broadly applies to all information, but generally information implies data that has been processed.
Jump to Section
Definitions of Data and Information
The definition of data and information can be fairly crossed at times. For example, some definitions of data include statistics and facts, which is true for structured or processed data. A more effective explanation comes from Wiki, “a set of qualitative or quantitative variables”, Wikipedia goes on to admit that data and information are often interchanged. It’s probably best said, that, the degree of ‘information‘ that can be obtained from a dataset will depend on its quality and form.
Data is probably best described from its Latin derivative, “thing”, an entity. Data could essentially be anything. However, data must contain some fact – a piece of information.
Information implies to “inform”, to pass on knowledge.
Data itself without connections may be meaningless, whereas information cannot be, it needs to have meaning. Information is not abstract, whereas data is.
Data is a fact, information is a fact about something or someone.
Data Processing
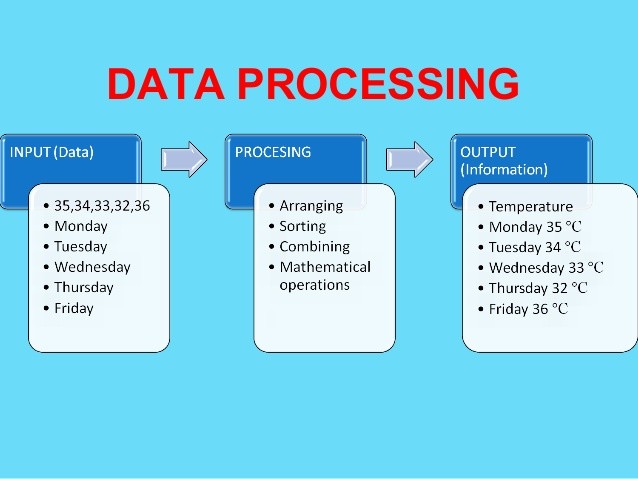
Data processing applies procedures to raw data to turn it into information. Data sets may be just figures, text excerpts, actions, which alone do not tell us anything. These pieces need to be correlated into information through finding connections in sets. This is the function of data processing.
Data processing collects, stores, cleans, transforms, and presents information from data sets in a valid way.
Without data processing, typically a data set cannot be very useful. Let’s take a quick look at how data processing makes a data set useful.
Data Processing, from Raw to Information
Raw data is primarily “unclean”. That is, it contains many errors, so first it needs to have errors removed, a term called cleaning. Without cleaning many erroneous correlations can be drawn.
For data processing on any platform, the data needs to be in the same format so that comparative data sets can be processed together. This may involve converting file types, rearranging, and reassigning data values, or converting units.
To provide meaningful information data sets need a range of functions which may include separating, sorting, and re-summarizing or aggregation. Important relationships need to be identified, similar items grouped, some data sets will need to be broken down into variables, and some data sets combined to provide larger data sets. The final product is then presented as information.
Information Processing
Information processing takes information and changes the form in order usually to define more meaning from it. In this sense, information processing has much more in common with data analytics than data processing.
Information processing concepts have their origin in psychology, which considers all observations as information. However, although only observation, there is still a meaning behind it, and it’s not raw data.
Thefreedictionary.com defines information processing as “the sciences concerned with gathering, manipulating, storing, retrieving, and classifying recorded information“. Many of the steps of data processing are the same in information processing, however the medium is different.
Wikipedia provides a more vague whilst also more definitive description, processing – a change in, information – an observable event or entity which provides some form of the answer to a question.
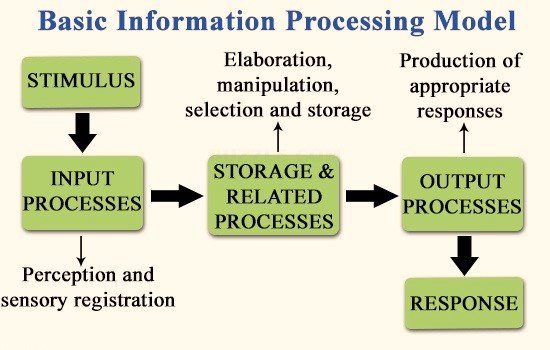
Information processing is a much broader term than data processing. It can mean for example changing (processing) a document (information) from screen to print, or the process of receiving a message. It can simply mean analyzing the world around us to draw conclusions. The important part is there is information: valid input, a change in that information, and a resulting question answered or conclusion drawn.
Information processing in computer terms refers to the use of algorithms to transform data. This is essentially the underlying or defining activity of computers, which is why computer sciences were initially defined as IT – information technology. Computers are information processors, however they do not do the information processing, they are a processing tool manipulated by their human user. An operator puts information in, then applies processing to it via the computer.
There are many parallels with information and data analytics. Data analytics is the stage of drawing conclusions from the information provided by data processing and also uses algorithms. Data analytics can be seen as another stage in data processing functions to provide more information for end users in decision-making capacities.
Psychology sees information processing as a primarily human function, and search for the term leads to many psychology definitions, however, especially with machine learning, this may not be strictly the case anymore. Excluding abstract applications, information processing is a science that needs reasoning, whether by AI or by humans.
Psychology can give us a clue to the fact that information processing is more of a higher cognitive skill than data processing, which is largely a matter of applying programs and repetitive techniques to data sets to look for patterns. That is data processing can often be automated by standard machine technology and computing, but from this standpoint, information technology can only be automated by machine learning. It requires higher thinking.
Conclusion
Data processing creates information. Information processing creates actions or decisions. While one can argue that all data is information or all information is data, this explanation gives a more practical application of the distinction from the discussion above.
A data processing function is meant to take raw data and turn it into meaningful information. Data analytics is a step that connects data processing to information processing, by extracting conclusions from processed data sets. From there information processing takes over.
Information processing is highly cognitive and usually needs to be conducted by a human or by artificial intelligence.
Without data processing, information processing is not possible. Without information processing, data processing has no purpose. The two are integrally linked.
If you are in the business of refining raw data, data processing is your tool. If you are on the decision and communications end, you need information processing. They are different steps in the overall process of fact-based technology.
I excel when it comes to making bespoke data dashboards and visualizations that users and clients absolutely love. Sharing about things I enjoy doing is my hobby, whether it's about a project, collaboration, feedback, or just simple how-to guides about visualization.
If you have something to ask or share, I'd love to hear from you!
- Business Intelligence Vs Data Analytics: What’s the Difference? - December 10, 2020
- Effective Ways Data Analytics Helps Improve Business Growth - July 28, 2020
- How the Automotive Industry is Benefitting From Web Scraping - July 23, 2020
1 thought on “What to Choose?Data Processing or Information Processing”