
Not a single industry can be completely immune to bad data and the effects can be devastating. This may sound dramatic but it is a fact. In the service industry, it will destroy your customer relationship. With respect to the marketing field, bad data means difficulty in identifying potential customers. Lets’ take a case of the healthcare industry, it could mean a matter of life and death! In logistics, it could mean delayed deliveries and loss of customers. Therefore, one has to know how to weed bad data to improve your business growth.
Once the data analyst has got the knack of identifying good data, he/she can provide insights.
Jump to Section
Ways To Weed Out Bad Data
Let’s take the example of a manufacturing unit. There are many aspects of the business enterprise affected by real-time data streams. The processes involved are:
- Procurement of raw materials
- Inventory
- Manufacturing process
- Marketing and advertising
- Sales and delivery
- After-sales service
- Customer relationships
- Payroll
- Accounting and taxation
- Compliances
All these activities cost money. But when Big Data contains bad data, the impact is in the form of an increase in operational costs. Therefore, your model must have an aggressive approach towards weeding out bad data. In order to implement the correct strategy for eliminating bad data, you have to:
1. Accept that there is bad data
Accepting that there is a problem, is the first step. This step will lead you closer to the solution. You will be able to track the deliberate or unintentional online activities. Suspicious activities of customers or potential customers that generate bad data.
2. Identify the bad data sources
Your model must identify the sources of bad data. The model should be able to segregate them by demographics, geographical region, etc.
3. Set in regulators
Design the model with parameters that controls the use and access. The parameters control which information about your organization is public. This will prevent harmful manipulation of data.
4. Preventive approach
Your algorithm must have a very aggressive way of tracking bad data sources. The algorithm should prevent such data-streams as much as possible. Checking the quality of the data at the source and not allowing it to mess up relevant data is vital. This approach will make your model dependable and provide accurate insights.
PERFECTING YOUR DATA MODEL TO WEED OUT BAD DATA
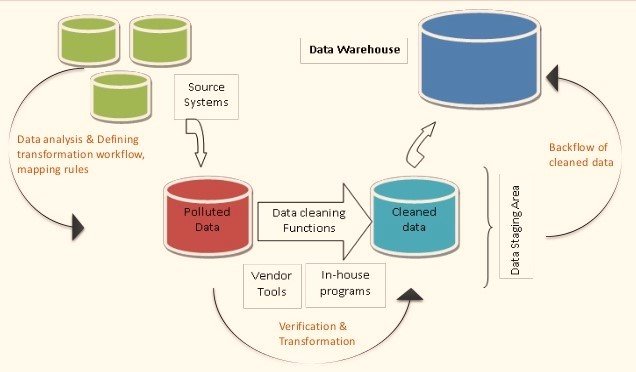
“Quality” of the real-time data streams is the key factor. It will ensure your client’s business moves in the right direction. The clients can achieve their business goals and objectives by making the right decisions. They can make the right business-related and financial decisions from accurate data analysis.
So that this process succeeds, your Business Intelligence model must eliminate bad data. All waste is bad, but waste in Big Data can be the end of a business. For example, if the model is not designed to track shadowy activities, they could miss dissatisfied employees or customers who deliberately enter the wrong data. This data will become a part of the data pool, resulting in inaccurate insights. Therefore, the only way to correct such situations is to use data analytics tools. To prevent them in the future or to track and remove waste or bad data, deploy good models. Provided that, so what exactly does your machine learning model have to do?
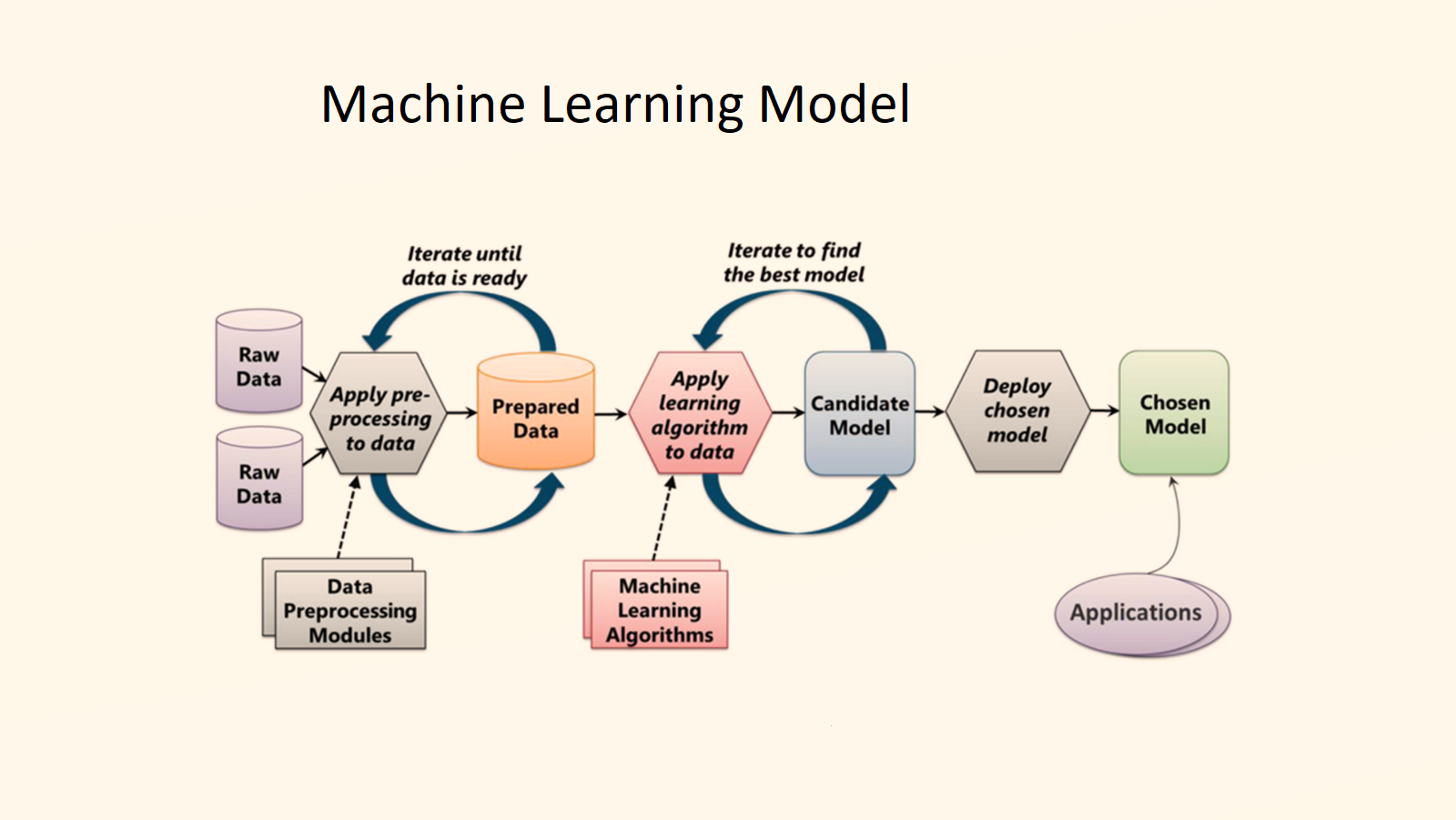
Your model must
- Identify the Key Performance Indicators (KPI) that need to be measured.
- Create a baseline for measuring each process and see how your data varies with changes in inputs.
- Set in “perfect measurement” parameters. See whether your data model meets these criteria with real-time streams.
- Accurately measure data during every business process.
- Analyze the data so that the irrelevant or erroneous data can be eliminated from the model.
- Create parameters to measure known poor-performing processes. Check if your data analytical model identifies them accurately.
- Add/modify parameters to remove redundancies in different business process. Ensure this, so that there is better efficiency.
- Design “warning” triggers in the model.
- Retest the model against varying inputs and outputs. In a way, it ensures that it is working on all parameters perfectly.
Measure Right Data
To implement these parameters in your algorithm, you will have to measure the right data. Right data also means tracking relevant data without missing many details.
So, before you start analyzing data sets, you have to first identify what needs to be measured. Then, you will have to map the information pertaining to the business process. Also, map them into subsets and track their efficiency in stages. Based on this information, measure the following:
- The number of reported inefficiencies in the processes.
- The short-term impact vis-à-vis loss of business.
- The cost of these processes that resulted in bad business processes.
- The accuracy of the predictive analysis that your data model carries out.
- Whether your model gives relevant and actionable insights. This can be done for the improvement of the business process.
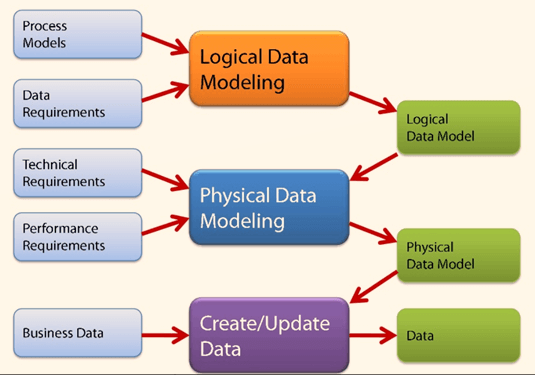
Identify correct Parameters
The success of your model will depend on having a comprehensive set of parameters. It has to be paired with a sufficient amount of testing of the model on real-time data. But Data Analysis is an ongoing process, so you also have to automate the process. This has to be done for continued measuring without human interference. Sometimes human errors can result in wrong insights. Getting real-time data in a service industry would involve data mining and querying. Whereas, in a manufacturing unit, the real-time data may come from digital sensors. Similarly, the electronic devices will also feed data to the data pool.
Assimilation of this data, storage, testing and sets will require a high-level of focus. Once you have collected the relevant information, create model data and test them. This is to ensure that your model is capturing data which is relevant and usable. You can test the data sets to check for accuracy of outputs. You have to be careful and not leave any subprocess behind.
With fine-tuning and retesting the information your model can provide the best insights. The testing process of Artificial Intelligence model will help to fine-tune the tool. This testing process can correct the anomalies of the model. In fact, it is the problems that will help you to perfect your data model. When you have a system to eliminate bad data. You can analyse a perfect set of relevant data. Then your Business Intelligence model will provide the most accurate and helpful insights.
Therefore, putting the improvements to your DA model itself is the most crucial stage. This has to be done perfectly for designing the best machine learning algorithm. It must be capable of self-improvement and self-correction without requiring human interference.
Understanding the existing data model & ask for feedback
Another aspect that can help you to perfect your model is by asking for feedback. Feedback from existing clients can help to improve the model. Ask people who use the tool whether there are any unprecedented bottlenecks. Such anomalies will help to detect their cause and take corrective action. Also, if any part of the Data Analytics process is slow in producing the necessary results. Furthermore, that part of the analysis can be modified and retested.
Sometimes, clients may be using specific hardware and tools that slow the process. Once the data analytics process is slow, this may cause problems with your model. Knowing the cause of bad outputs at the client’s end will help understand the issue. The issues despite providing the perfect data model will help you to solve the problems. You have the complete feedback and the list of issues the clients have faced.
While using your data model, you can prioritize them by their impact on the business process. The issues that cause major delays in the processes have to be solved first. You may have to form a team to improve the problematic process. They will require legitimate access to the data sets. Once corrective action is taken, you will have to retest the model. We have to continue that for a few times more using different data sets so that there are absolutely no errors.
At this stage, it becomes imperative for you to set in parameters. The parameters act as warning triggers if the process fails again. In a way, the easiest way to do so is to leave your measurement parameters as they are. The parameters should be set within limits or boundaries for them that act as triggers. Any change in the boundaries sets off the triggers. You will be able to identify what is causing the problem and you can solve it immediately. With accurate analysis and insights, your client’s business will experience increased efficiency. Moreover, they also encounter better speed, quality products, optimum use of raw materials. This helps the company do timely deliveries, better customer relationships etc.
Conclusion
Your data model will be very reliable and dependable when you weed out bad data. Therefore, a reliable data model will help in improving your customer base. Weeding out bad data is a continuous process. It is about continuously improving your DA model. When you are improving, you are throwing away bad information continuously. So, your DA model will be the most reliable one if it accesses Big Data in real-time. Similarly, the model should use the algorithms that have the capability to improve themselves. This is how to weed bad data to improve your business growth as well as that of your clients.
I excel when it comes to making bespoke data dashboards and visualizations that users and clients absolutely love. Sharing about things I enjoy doing is my hobby, whether it's about a project, collaboration, feedback, or just simple how-to guides about visualization.
If you have something to ask or share, I'd love to hear from you!
- Business Intelligence Vs Data Analytics: What’s the Difference? - December 10, 2020
- Effective Ways Data Analytics Helps Improve Business Growth - July 28, 2020
- How the Automotive Industry is Benefitting From Web Scraping - July 23, 2020