
Before starting ahead, let’s first go through the checklist required to import the data correctly into R. Here we go…
- If you work with spreadsheets, and the first row is usually reserved for the header while is used for identifying the sampling unit.
- If you want to concatenate word, inserting a. in between a. in between two words instead of space.
- Shortest names are preferred over the longer name.
- Try to avoid using names that contain symbol such as ?,$,%,^,&,*,(,),-,#,\,/,[,],{ and }.
- Delete any comments, If you have created in .xlsx file to avoid extra columns and NA to be added to file.
- Make sure, if there are any values mismatching in your dataset, will be indicated as NA.
Jump to Section
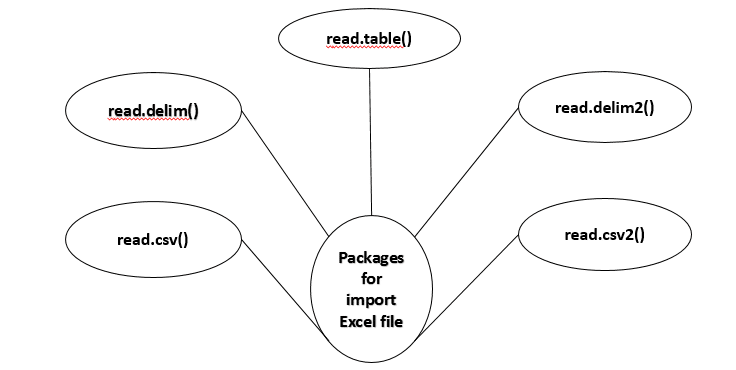
Utils Package
- read.table()
- read.cvs()
- read.csv2()
- read.delim()
- read.delim2()
Import txt file
read.table():
Suppose (.txt) or a (tab-delimited) file is available, you can easily import it with the basic R function read.table(), therefore:
df = read.table(“filename.txt”, header = FALSE, sep = ‘/’ , strip.white = TRUE, na.strings = “EMPTY”)
The strip.white function allows to indicate whether you want the white spaces. Furthermore, It is only used that na.strings indicates which string should be interpreted as NA value. Finally, result will look like as:
Content of .txt
1/6/12:01:03/0.50/WORST
2/16/07:42:15/0.32/BEST
3/19/12:01:29/0.50/”EMPTY”
4/13/03:22:50;0.14/INTERMEDIATE
5/8/09:30:03/0.40/WORST
Which would result in:
V1 V2 V3 V4 V5
1 6 12:01:03 0.50 WORST
2 16 07:42:15 0.32 BEST
3 19 12:01:29 0.50 “EMPTY”
4 13 03:22:50 0.14 INTERMEDIATE
5 8 09:30:03 0.40 WORST
Note: read.table() argument is also set as TRUE, which means that if rows have unequal lengths, and blank fields will be added implicitly.
read.csv() and read.csv2():
It functions are frequently used to read spreadsheets saved with the extension .csv or Comma Separated Values. So, remember that both function have the header and fill arguments set as TRUE by default. In conclusion,
#Content of .csv
1 ; 6 ; 12:01:03; 0.50; WORST
2 ; 16 ;07:42:15;0.32 ; BEST
3 ; 19 ;12:01:29; 0.50; “EMPTY”
4 ; 13; 03:22:50; 0.14 ; INTERMEDIATE
5 ; 8; 09:30:03; 0.40; WORST
uniquely this file are .csv file:
1 , 6 , 12:01:03, 0.50, WORST
2 , 16 ,07:42:15,0.32 , BEST
3 , 19 ,12:01:29, 0.50, “EMPTY”
4 , 13, 03:22:50, 0.14 , INTERMEDIATE
5 , 8, 09:30:03, 0.40, WORST
To read.csv file that use a ( , ) as separator symbol and you can use the read.csv() function. Finally you will get like this:
df = read.csv("filename and extension of your file", header = FALSE, quote = "\"", stringAsFactors = TRUE, strip.white = TRUE)
Note that the quote arguments denotes whether your file uses a certain symbol as quotes: in the command above , you pass\” or the ASCII quotation mark (“) to the quote argument. To make sure that R takes into account that symbol that is used to quote characters.
Hence, the stringAsFactors argument allows us to specify if the string converts into factors or not.
For file where fields are separated by a (;), you use the read.csv2() function:
df = read.csv2("<name and extension of your file>", header = FALSE, quote = "\"", dec = ".", row.names = c("M", "N", "O", "P", "Q"), col.names = c("X", "Y", "Z", "A", "B"), fill = TRUE, strip.white = TRUE, stringsAsFactors = TRUE)
Note that the decimal argument allows you to specify the character for the decimal mark. Make sure, to specify this values will be interpreted as separate categorical variables. So, The col.names argument, completed with the c() function that concatenates column names in a vector.
Furthermore, specifies the column names in the first row. This can be easily used if your file does not have a header line, R programming will use the default variable names V1, V2,…etc. Column names can override this default and assign variable names. So, the argument row.names specify the observation names in the first column of your data set.
#content of .csv
1 ; 6 ; 12:01:03; 0.50; WORST
2 ; 16 ;07:42:15;0.32 ; BEST
3 ; 19 ;12:01:29; 0.50; “EMPTY”
4 ; 13; 03:22:50; 0.14 ; INTERMEDIATE
5 ; 8; 09:30:03; 0.40; WORST
And it will would result in the following data frame:
M 1 6 12:01:03 0.50 WORST
N 2 16 07:42:15 0.32 BEST
O 3 19 12:01:29 0.50 “EMPTY”
P 4 13 03:22:50 0.14 INTERMEDIATE
Q 5 8 09:30:03 0.40 WORST
Furthermore, that the vector that you use to complete the row.names or col.names arguments need to be of the same length of your dataset.
read.delim() and read.delim2()
They are variants of the read.table() function. They are similar to the read.table() function, and except for the fact that the first line that is being read is a header is the attribute names for read.delim and read.delim2, while they use a tab as a separator instead of a whitespace, comma or semicolon. As a result, it also contains the fill argument set to TRUE, Which means that blanks field will be added to rows of unequal length. read.delim() can be used to import the dataset file (.txt, cvs, .xlsx etc) in the following ways:
df = read.delim2("<name and extension of your file>", header = FALSE, sep = "/" quote = "\"", dec = ".", row.names = c("O", "P", "Q"), fill = TRUE, strip.white = TRUE, stringsAsFactors = TRUE, na.strings ="EMPTY",as.is = 3, nrow = 5, skip = 2)
This function uses a decimal point as the decimal mark, as in: 3.1415. The n-rows argument specifies that only five rows read from the original data. Firstly, the as.is is used to suppress factor conversion for a subset of the variables in your data. Seems if they were not otherwise specified: just supply the argument with a vector of indices of the column that you do not want to convert, like much in the command above, or give in a logical vector with a length equal to the number of columns that are read. If the argument is TRUE, Factor conversion suppress everywhere.
Example:
1 / 6/ 12:01:03/ 0.50/ WORST
2 / 16 /07:42:15 /0.32 /BEST
3 / 19 /12:01:29 /0.50
4 / 13 /03:22:50 /0.14 /INTERMEDIATE
5 / 8 / 09:30:03 /0.40 /WORST
So, you will get the following result:
V1 V2 V3 V4 V5
3 19 12:01:29 0.50
4 13 03:22:50 0.14 INTERMEDIATE
5 8 09:30:03 0.40 WORST
For read.delim() sets to deal with decimal point. We can already probable that there is different way to deal with files that have decimal commas.
So, basically we can use different function read.delim2() for those files:
Syntax:
df = read.delim2("<name and extension of your file>", header = FALSE, sep = "\t" quote = "\"", dec = ".", row.names = c("M", "N", "O"), col.names = c("X","Y","Z","A","B"),colclasses = (rep("integer",2), "date","numeric","character"), fill = TRUE, strip.white = TRUE, na.strings ="EMPTY", skip = 2)
Furthermore, read.delim and read.delim2 defines for reading delimited files, defaulting to the TAB character for the delimiter. Noteworthy, Notice that both header and fill holds TRUE in these variants, and the comment character shows the result ‘disable’
In conclusion, the skip arguments specify that from the first two rows if the dataset does not read into R. Secondly, column classes allows you to specify a vector of classes for all column of your dataset. In addition, the dataset has given columns with two type of integers, replicating the class “integer”, the second class of “date”, the third of “numeric” and lastly, the fourth of “character”.
As a result, The rep argument indicates the replication of the integer type for the two first column. Also, the delimiter separator defines as (“\t”), an escape code that designates the horizontal tab.
I excel when it comes to making bespoke data dashboards and visualizations that users and clients absolutely love. Sharing about things I enjoy doing is my hobby, whether it's about a project, collaboration, feedback, or just simple how-to guides about visualization.
If you have something to ask or share, I'd love to hear from you!
- Business Intelligence Vs Data Analytics: What’s the Difference? - December 10, 2020
- Effective Ways Data Analytics Helps Improve Business Growth - July 28, 2020
- How the Automotive Industry is Benefitting From Web Scraping - July 23, 2020