
Nowadays, searching on the application’s web server is widely increasing day by day. Consequently, data is getting huge within the server. A relational database server having petabytes of data can take a lot of time when searching a record. The solution comes with Elasticsearch. In short words, searching is lightning fast with this technology.
In this article, I will explain what exactly this technology is, as well as its advantages and disadvantages. After that, I will explain how to setup Elasticsearch.
Jump to Section
What Is Elasticsearch?
Elasticsearch is an open-source distributed full-text search database with RESTful search and an analytics engine. It internally stores data in the document in JSON format. Then, you query them for retrieval. Basically, this data is schema-less, using some default settings to index the data unless you provide mapping as per your needs. Elasticsearch uses Lucene Standard Analyzer for indexing automatic type guessing and high precision. Elasticsearch is lightning fast and highly scalable and used by highly respected organizations like Wikipedia and Linkedin, to name but a few.
How Does Elasticsearch Work?
When you search from a traditional SQL database that is schema-based. It searches in single-node only, and it takes time to execute a query because of its schema-based nature. While data is distributed in Elasticsearch and it searches data horizontally in each node, it becomes highly scalable and super fast. This is so because the searching is done by many nodes simultaneously.

When we make a search operation in Elasticsearch, it uses the memory, or RAM, of each node. The search becomes faster because many nodes are working together. Let me explain some basic building blocks and synonyms that will help you understand distributed nature of ES.
1. Index: An index can be understood as a container of data. I will explain the index with an example later on.
2. Shard: Shard can be understood as a container of indexes because all indexes are stored in shards. All the nodes connected with the Elasticsearch must have at least one shard. We can store an index in multiple shards on the same node.
3. Replicas: Replica is nothing but a copy (or you can say duplicate of the shard). However, it does not make any sense to have a replica on the same node or machine. That is why Elasticsearch makes a replica of shards to each of the other nodes so that there will be no impact of data if one node gets a failure.
4. Role nodes: All the machines or nodes connected to the Elasticsearch cluster can have different roles. There are three different roles, which are the data node, the master node, and the client node. The main node, where default installation was done, will have all three roles.
The Job of Role Nodes
Each role node has a specific job. Let’s discuss each one of them:
- Data node: Data nodes basically contain all the data, like indexes and shards. The primary role of these nodes is to only keep all the data. They do not perform the execution of any query requests.
- Client node: This node acts as an entry point for Elasticsearch queries. This node receives all the queries and sends them to data nodes
- Master node: This node maintains the Elasticsearch cluster and maintains the state of the cluster.
Features of Elasticsearch
- Scalable up to petabytes: Elasticsearch is scalable up to petabytes of structured and unstructured data.
- Replacement of document store: Elasticsearch can be used as a replacement for document stores like MongoDB and RavenDB.
- Uses denormalization: Elasticsearch uses denormalization to improve the search performance.
- Popular search engine: Elasticsearch engine is one of the well-known endeavor web crawlers, that is as of now being utilized by numerous huge associations like The Guardian, Wikipedia, StackOverflow, GitHub, etc.
- Open source: Elasticsearch is open source and available under the Apache license version 2.0.
Advantages of Elasticsearch
Platform independent: Elastic search is developed on Java, which makes it compatible with almost every platform. It can be used in any machine where the java runtime environment is running.
Elasticsearch is real-time: Search in the Elasticsearch engine is super-fast. Data is searchable as soon as added to the engine.
Elasticsearch is distributed: It consists of multiple software components that are on multiple computers but run as a single system makes it easy to scale and integrate into any big organization.
Creates backups: Creating full backups is easy by using the concept of the gateway, which is present in Elasticsearch creates a replica of each shard. This is useful for protecting against hardware failures. Replication of shards will prevent the loss of data.
Multi-tenancy: Elasticsearch is capable of serving multiple customers within a single instance when compared to Apache Solr.
JSON-based response: Elasticsearch uses JSON objects as responses, which makes it possible to invoke the ES server with a large number of different programming languages. This is true because most of the programming languages supporting JSON.
Disadvantages of Elasticsearch
Supports JSON only: Elasticsearch does not have multi-language support in terms of handling request and response data (only possible in JSON) unlike in Apache Solr, where it is possible in CSV, XML, and JSON formats.
Split-brain situations: Elasticsearch also has a problem with Split-brain situations but in rare cases. The split-brain situation is created during cluster reformation. When one or more nodes fail in a cluster, the cluster reforms itself with the available nodes.
The Installation Process of Elasticsearch
Please follow the below-given steps to install Elasticsearch.
1: Press window+R and hit enter. It will open the command prompt in your windows operating system.
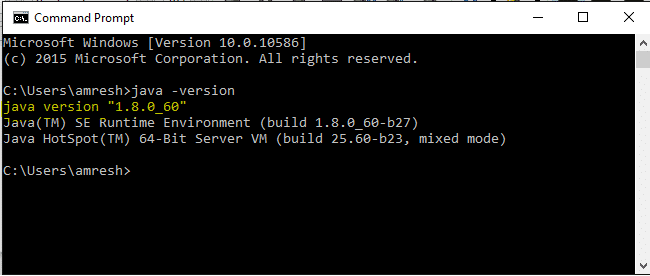
2: Run the below-given command to check the minimum version of Java installed on your computer, it should be Java 7 or a higher version. To see your current version of java installed on your machine, use the command in the below image.
3: Download Elasticsearch from www.elastic.co. For Windows OS, download the ZIP file.
4: You just need to unzip the downloaded zip package.
5: Now go to the Elasticsearch home directory. Inside the bin folder, run the elasticsearch.bat file directly from the windows explorer or you can do the same using command prompt as given below two commands.
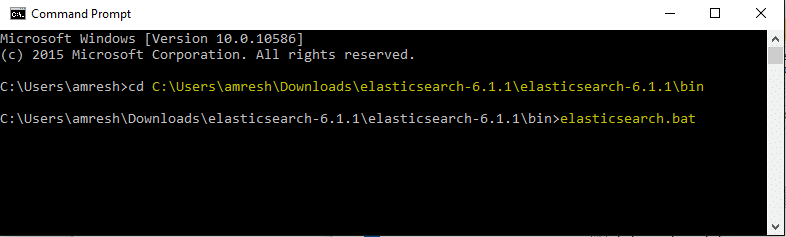
You will get an error. This is because you have not set the java runtime environment path in environment variables to “C:\Program Files\Java\jre1.8.0_31” or the location where you installed java.
Alternatively, you can set the java run-time environment path temporarily using the command given in the below image.
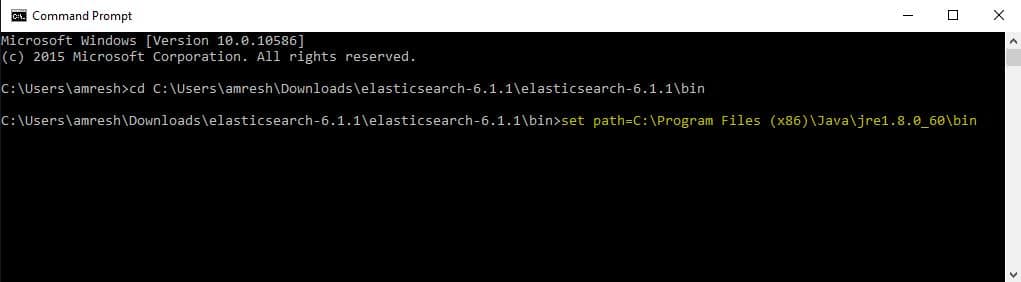
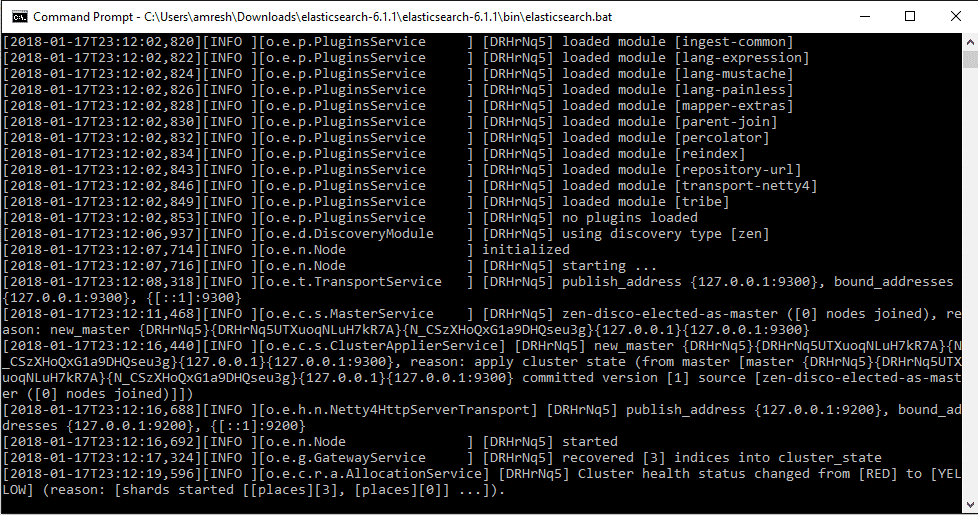
Repeat step 5 once you set the java run-time path from the command prompt as given in the above screen and you will see the output as seen in the below image.
5: You can access Elasticsearch API using http://localhost:9200, where the Default port for the web interface is 9200. You can change it by changing the HTTP port inside of the elasticsearch.yml file present in the bin directory. You can check if the server is running up and browsing http://localhost:9200.
You will get a JSON object, which is nothing but information about the installed Elasticsearch as shown in the below image.
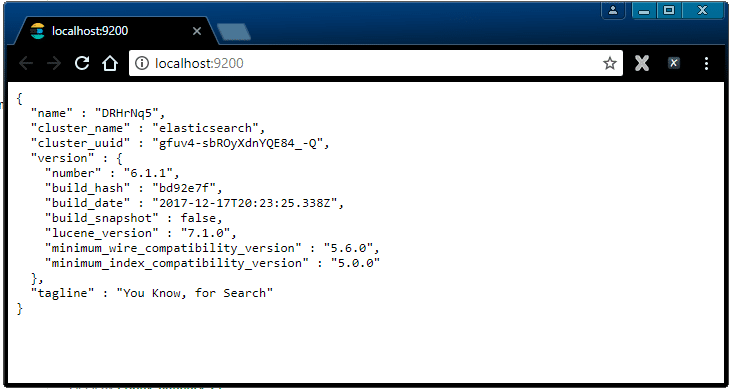
That’s all – you have successfully installed Elasticsearch on your machine.
CRUD Operation in Elasticsearch
Elasticsearch is a REST API that you interact with over HTTP by sending certain URLs, and in some cases, HTTP bodies composed of JSON objects that you use to give commands to the cluster. So far, we have tried the GET requests only. It will be difficult If you work with POST commands. So, we need a tool that will help us make these requests to the cluster.
For CRUD (Create, Read, Update, Delete) operations, we have logical equivalents in HTTP methods (HttpPost, HttpGet, HttpPut, and HttpDelete), which makes it easy to interact using standard methods. So, instead of using the browser, we will use tools like Fiddler or postman which facilitate easy HttpPost, HttpGet, HttpPut, and HttpDelete requests.
Fiddler: You can install Fiddler2 from www.telerik.com/fiddler as a front end for your Elasticsearch.
Postman: You can install Postman from https://chrome.google.com/webstore/detail/postman/fhbjgbiflinjbdggehcddcbncdddomop?hl=en as a front end for your Elasticsearch.
Note: This version of the Postman is for chrome you can download postman as per your requirements. For this tutorial, I will be using Postman for making API requests – you can use any other tool.
Creating Index Using Elasticsearch REST API
An index is a collection of documents. It is similar to a database schema in the traditional database world. In the configure window of Postman, you can hit the address to add an index, and if you want, the type/mapping also using HTTP Put method, for example, −
http://localhost:9200/countries
You will get a JSON format message as shown in the below screenshot.
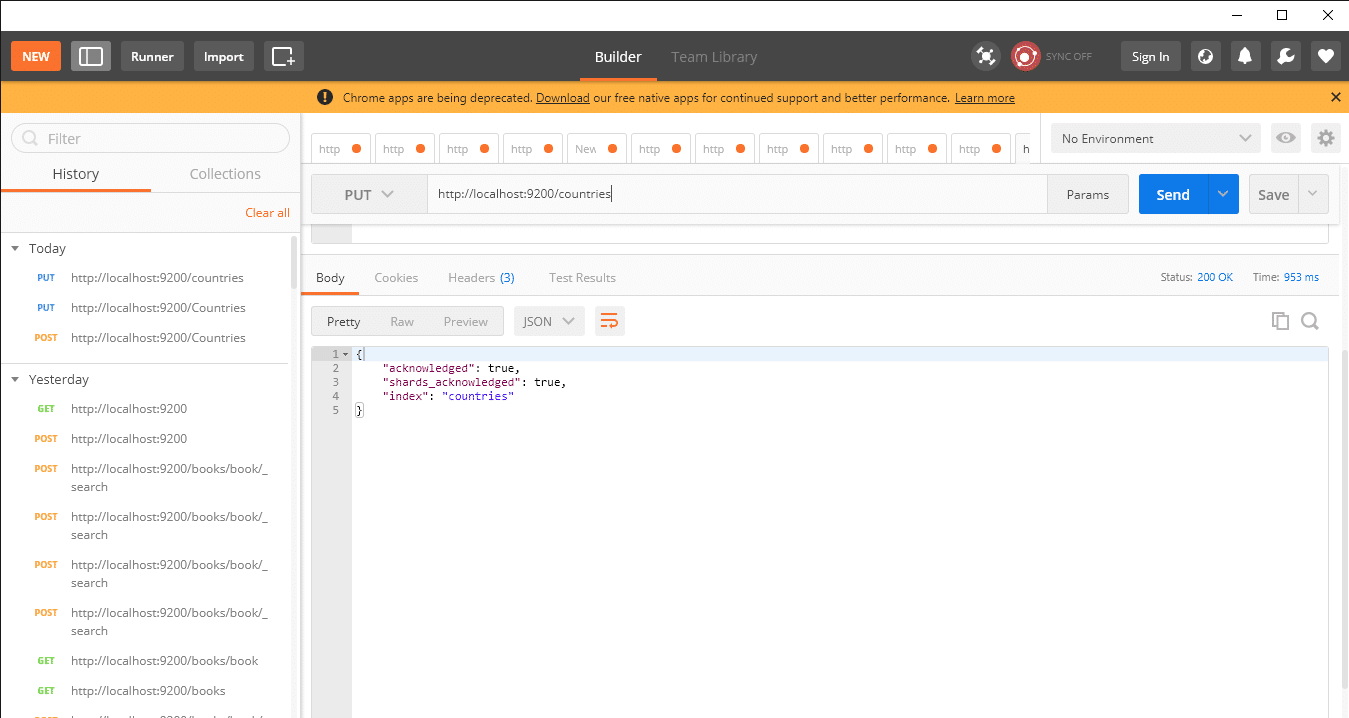
Adding data to recently created index using REST API
So far, we have created an index with the name countries. Now, we will add a country to index countries using HttpPost composed of a JSON object as shown in the below image.
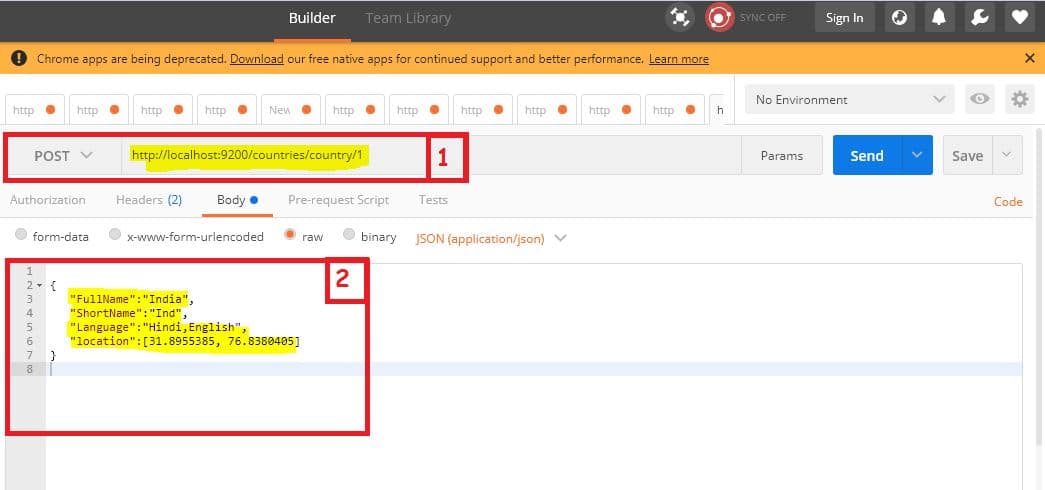
Note: Repeat this process to insert more country data.
Retrieving data from the recently created index using REST API
To retrieve data from the index, we need to make a post request composed of a JSON query object. the query will run on the server and return back the result please see the below image for an example.
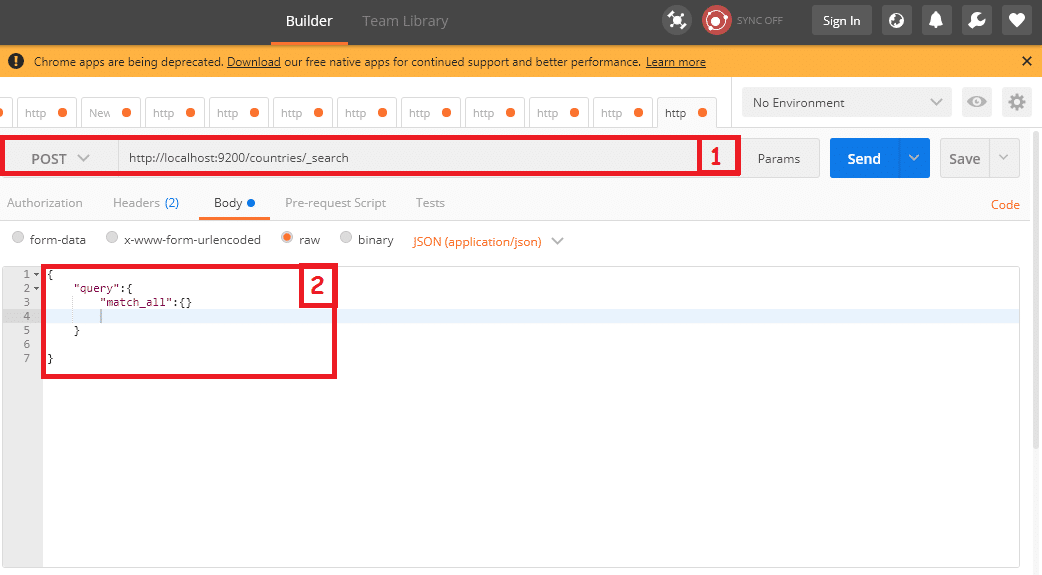
As you can see in the above-highlighted box 1, we are posting a request to URL http://localhost:9200/countries/_search where countries are the recently created index and _search will be used internally by the Elasticsearch for a search operation.
Highlighted box 2 contains a JSON object and that is going to compose with the request. This JSON object shows that the query will get all the data from index countries.
Output
{
"took": 287,
"timed_out": false,
"_shards": {"total": 5,"successful": 5,"skipped": 0,"failed": 0},
"hits": {
"total": 2,
"max_score": 1,
"hits": [
{
"_index": "countries",
"_type": "country",
"_id": "4",
"_score": 1,
"_source": {
"FullName": "Bangladesh",
"ShortName": "Bng",
"Language": "Urdu,Bangla",
"location": [31.8955385,76.8380405]
}
},
{
"_index": "countries",
"_type": "country",
"_id": "1",
"_score": 1,
"_source": {
"FullName": "India",
"ShortName": "Ind",
"Language": "Hindi,English",
"location": [ 31.8955385, 76.8380405 ]
}
}
]
}
}
The above example gets all country data in one go, but we can retrieve the country record for a specific one. We need to add country id in the URL to get one country record as shown below.
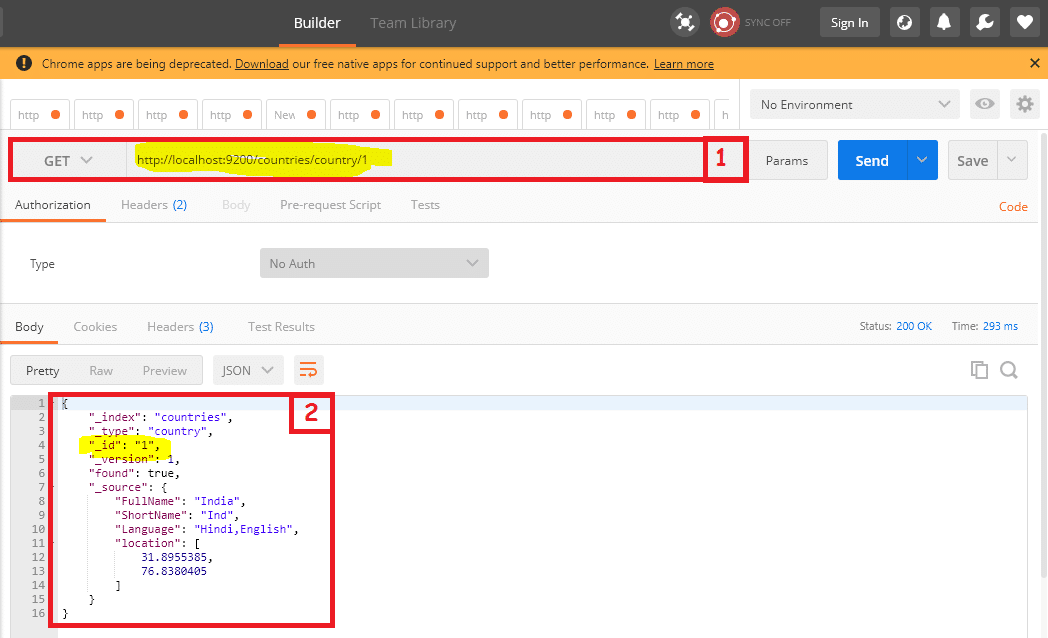
As you can see in the above-highlighted box1 we are making a get request through postman and passing id for country data ( http://localhost:9200/countries/country/1). Here 1 is the id for India similarly, we have id 2 for Pakistan, 3 for Nepal, and so on. If you want to get data for Pakistan you can pass 2 at the End of the URL.
Final Words
In this article, we have learned what Elasticsearch is and how it works, what are the features, and why we should use it. We have also learned about Inserting the data and its further retrieval using REST APIs. In my upcoming articles, we will learn more about Elasticsearch REST APIs. Stay connected for more updates!
- Difference Between SQL and MySQL - April 14, 2020
- How to work with Subquery in Data Mining - March 23, 2018
- How to use browser features of Javascript? - March 9, 2018