
Data Mining is the only process of sorting the large data sets in a quick manner. Also, it identifies each record with its relationship to solve through the data analysis skills. Data mining includes such wonderful methods for data analysis like Machine Learning, Statistics, and Database Systems. The Main purpose of data mining is to extract the information from large data set and transform it into a useful data structure.
In this article, we will learn about how subquery helps to find the better result with the help of data mining but before going ahead we need to learn what is subquery and its working relationship with data mining.
Jump to Section
What is Subquery in Data Mining
A subquery is a query, which comes inside another query in SQL, this is also known as a Nested query or Inner query. This returns data that is used in the main query on behalf of condition inside parentheses. Therefore, A subquery is embedded within WHERE clause, FROM and SELECT clause. You can see the exact syntax of a subquery as follows.

- A subquery always works within the WHERE Clause of other SQL SELECT command.
- It is always enclosed within parentheses.
- Also, you can use these operators, much like as >, <, or =.
- The nested query runs first before its main (Parent) query. So, the results of a nested query pass to the outer query.
- You can not use ORDER BY command within nested query but you can use ORDER BY command in the main query.
- An inner query always consists of one selected column in the SELECT clause until the multiple columns compare to its selected columns.
- The BETWEEN clause cannot be used in the subquery, However, you can use BETWEEn clause in the main query.
You can use all common commands like SELECT, INSERT, UPDATE and DELETE in the subquery for getting the result better through the help of data mining process.
Subqueries with the SELECT Command
There is a common syntax for writing a subquery as given below,
SELECT column_name [, column_name ] FROM table1 [, table2 ] WHERE column_name OPERATOR (SELECT column_name [, column_name ] FROM table1 [, table2 ] [WHERE] )
So, let’s take a real example, we assume a table like as given below;
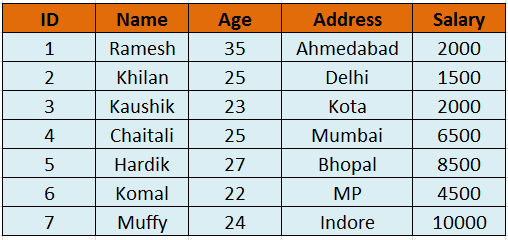
So, let’s start with a Select command for the following output,
SELECT * FROM CUSTOMERS WHERE ID IN ( SELECT ID FROM CUSTOMERS WHERE SALARY > 4500 )
Finally, the output will look like this.
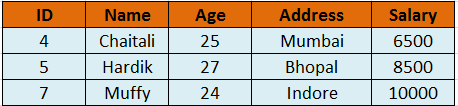
You have seen the simple example of insert the data in the table. Therefore, we take another example for more clarification. We need to create two table tblProducts and tblProductSales and insert sample data for the same.
Script to create table tblProducts
Create Table tblProducts
(
[Id] int identity primary key,
[Name] nvarchar(50),
[Description] nvarchar(250)
)
Create Table tblProductSales
(
Id int primary key identity,
ProductId int foreign key references tblProducts(Id),
UnitPrice int,
QuantitySold int
)
statement 1
Insert into tblProducts values ('TV', '52 inch black color LCD TV')
statement 2
Insert into tblProducts values ('Laptop', 'Very thin black color acer laptop')
statement 3
Insert into tblProducts values ('Desktop', 'HP high performance desktop')
statement 4
Insert into tblProductSales values(3, 450, 5)
statement 5
Insert into tblProductSales values(2, 250, 7)
statement 6
Insert into tblProductSales values(3, 450, 4)
statement 7
Insert into tblProductSales values(3, 450, 9)
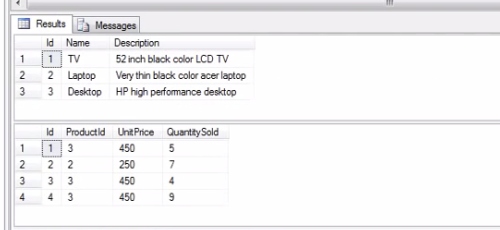
Finally, the output for the following table.
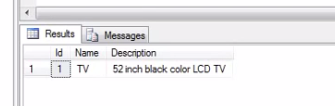
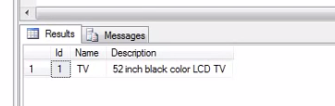
Now, I want to retrieve products that are not at all sold,
Select [Id], [Name], [Description]
from tblProducts where Id not in (Select Distinct ProductId from tblProductSales)
Finally, the output as follows.
How Subquery works with Joins
By using joins and it gives you the same results. So, Let’s create the query for the same as follows,
Select tblProducts.[Id], [Name], [Description] from tblProducts left join tblProductSales on tblProducts.Id = tblProductSales.ProductId where tblProductSales.ProductId IS NULL
When you execute the code, you get the same output that we achieved above.
Hence, you have seen how to use a subquery with WHERE clause.
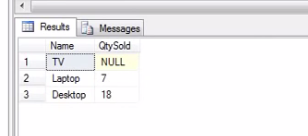
In addition, let’s have a look, a subquery in the SELECT clause. So, I want to retrieve the NAME and TOTALQUANTITY sold by using a subquery.
Select [Name], (Select SUM(QuantitySold) from tblProductSales where ProductId = tblProducts.Id) as TotalQuantity from tblProducts order by Name
Hence, you get the same output.
If you use joins, then you can get the same out as above,
Select [Name], SUM(QuantitySold) as TotalQuantity from tblProducts left join tblProductSales on tblProducts.Id = tblProductSales.ProductId group by [Name] order by Name
Finally, you get the Output:
From above examples, it seems clear now that, a subquery simply use a select statement, that gives a single value in return and also inner query inside a SELECT, UPDATE, INSERT, or DELETE command.
What to choose SubQueries or Joins in Data Mining
This is something very confusing because some of the developers get confused which one should be used for sorting the data in data mining. But remember both the function gives the same result but they have their own capabilities so let’s understand through a table.
we assume data in both the tables tblProducts and tblProductSales.
400,00 data in the tblProducts table
600,00 data in tblProductSales tables
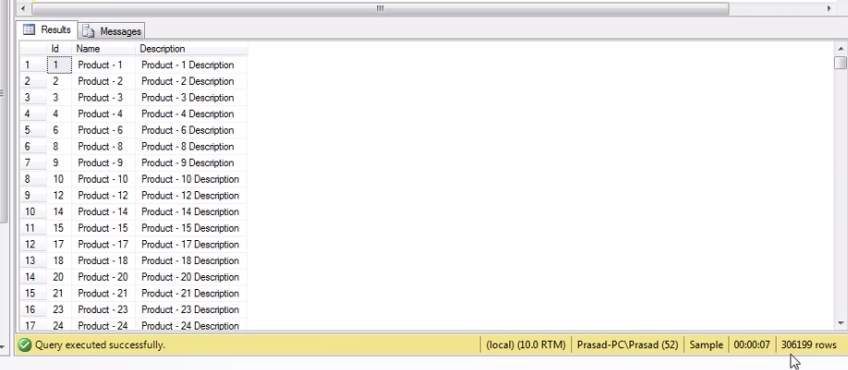
When I execute the command, then, you get 306,199 rows in 6 seconds
Select Id, Name, Description from tblProducts where ID IN ( Select ProductId from tblProductSales )
Finally, you get the output as follows,
For this reason, please swipe the command and execute plan cache by using the following T-SQL statement.
CHECKPOINT; GO DBCC DROPCLEANBUFFERS; -- Clears query cache Go DBCC FREEPROCCACHE; -- Clears execution plan cache GO
Now, execute the command by using joins. Note that we get the exact same 306,199 rows in 6 seconds.
Select distinct tblProducts.Id, Name, Description from tblProducts inner join tblProductSales on tblProducts.Id = tblProductSales.ProductId
Please Note: We are using automated SQL script to insert large amount of random data.
According to MSDN, a join gives better performance. Else, the subquery must be passed for each result of the main query. As a result, a joins gives the better results instead of a subquery.
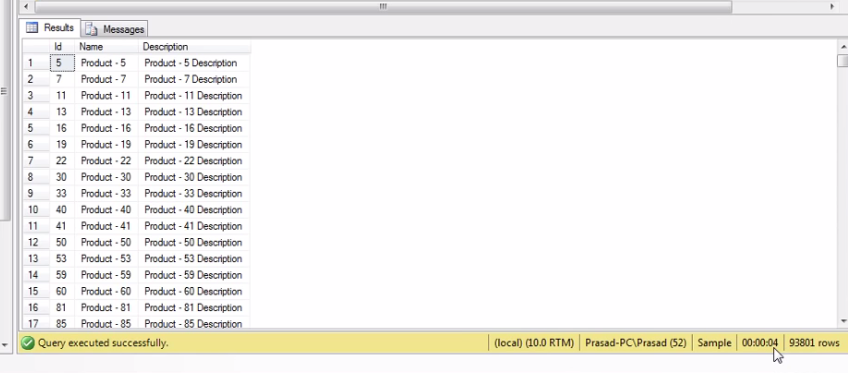
The above query command gives the products result that we have not sold for once. When I run the query I get 93,801 rows in 3 seconds
Select Id, Name, [Description] from tblProducts where Not Exists(Select * from tblProductSales where ProductId = tblProducts.Id)
Finally, you get the output as follows,
When I run the query by using joins, I get the same result 93,801 rows in 3 seconds.
Select tblProducts.Id, Name, [Description] from tblProducts left join tblProductSales on tblProducts.Id = tblProductSales.ProductId where tblProductSales.ProductId IS NULL
In conclusion, joins work faster than subqueries, but if we see in reality, it all depends on the plan of execution that is made by SQL Server. Hence, if you want to get the output in a quick manner or you do an extraction of data then go with joins for data mining.
Conclusion
In this article, you may find both results set with subquery and use of joins instead of using the subquery while working in mining the data with any analytic tool like SQL, Hadoop, and Big Data. A subquery verifies two identities with proper format for the IN clause. But, if we talk about a large number of data in the database server, use joins queries rather than a subquery because joins takes less time to get the output in data mining.
- Difference Between SQL and MySQL - April 14, 2020
- How to work with Subquery in Data Mining - March 23, 2018
- How to use browser features of Javascript? - March 9, 2018