
Jump to Section
Overview
This blog is completely related to performance and improvement of a database. So, in case, you are scratching your head for improving the performance of your database, then keep calm and go through my blog post for satisfying your quench for the required information!
Database plays a most important role in the performance of any application and everybody wants a fast response on their data retrieval process. That’s why there’s a need to design the best database that claims to provide high performance during data manipulation.
But, but, but…things don’t come that easy! Hence, it can be stated that there is no straightforward way to define the best performance but we can definitely choose multiple ways for improving our database performance.
In this article, I am going to define a step-wise procedure including index, stored procedure, the best way to write the query etc. for improving your database’s performance. So, what are we waiting for??? Let’s get started…
1. Choosing the Appropriate Data Type
Choosing the right data types for your tables, stored procedures and variables not only improves the performance by ensuring a correct execution plan, but it also helps in improving the data integrity by ensuring that the correct data is stored in a database.
For example, I have an Employee Table and it has a code field. The length of the code may vary from 3 to 8, hence, in this case, instead of selecting CHAR (8), we can use the VARCHAR (8) data type. Try to choose the smallest data type that works for each column. Choosing an appropriate data type of a column in order to avoid explicit and implicit conversions can serve your cause because both are costly in terms of time to take for conversion.
2. Create Index, If Required
An index can be used to efficiently find all row matching to some column in your query and then walk through only that subset of the table to find exact matches. In case, you don’t have access to indexes on any column in the WHERE clause, the SQL server has to go through the whole table to check every row to see if it matches, which may be a slow operation on big tables. Some points must be kept in mind while creating an index:
- Do not create an index on columns that contain a high number of null values.
- Do not create indexes on columns that are frequently manipulated.
- Keep an index key short.
- Create indexes with a minimum percentage of duplicated values.
3. Use Chunk of Indexes rather than a Large Index
One can easily create multiple indexes per table in the SQL Server. However, Small or Narrow indexes can provide more options than a wide composite index. Note that, Statistics are only kept for the first column of a composite index in an index, so multiple single-column indexes ensure statistics are also kept in that column.
4. Index on All Foreign Keys
As we know mostly Foreign keys are used in joins. So that if an index creates on foreign keys always beneficial and performance can be the increase.
5. Where We Need to Create Index?
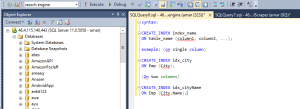
We need to create an index on columns used in a WHERE clause and used in aggregate operations, such as GROUP BY, DISTINCT, ORDER BY, MIN, MAX and so on. Below is the example, how to create index:
6. Remove Unnecessary Index
An index is needed to be maintained even if they are not in use. So, it is quite important to remove the use of all unused indexes. This can eventually help in improving your Database performance and will also help in clearing off the unnecessary clutter.
7. Avoid Use of *(star) With Select Statement
On SELECT *, you’re often extracting more columns from the database than your application really needs for functioning. This, in a way, causes more data to move from the database server to the client, slowing the access and increasing the overall load on your machines, as well as taking more time to travel across the network.
This is especially true when someone adds new columns to underlying tables that didn’t exist and weren’t needed when the original consumers coded their data access. Instead of doing this, pass the name of really required columns in query results.
Good to have:
SELECT column1, column2, column3 FROM Table1
Avoid this:
SELECT * FROM Table1
8. Avoid Use of Count(*)
Avoid use of count(*) due to performance, instead of this you can use count(1).
Good to have:
SELECT count(1) from Table1
Avoid this:
SELECT count(*) from Table1
9. EXISTS Better Than IN
During the use of IN operator, the SQL engine will fetch and scan all the records from the inner query. Whereas, on the other side, the during the use of EXISTS, SQL engine will lead to quick results on founding the required match.
EXISTS can be termed as a much quicker and faster way in comparison the IN Query because for the IN Query SQL first collects all the data of the sub-query.
Good to have:
SELECT Column1, Column2, Column3 FROM Table1 WHERE Column1 EXISTS (SELECT Column1 FROM Table2)
Avoid this:
SELECT Column1, Column2, Column3 FROM Table1 WHERE Column1 IN (SELECT Column1 FROM Table2)
10. Avoid Use of Cursor
A Cursor work towards performing a row by row function. The use of Cursor forces the database engine to repeatedly managing the locks, fetch the rows and transmit the results. Read-only and Forward-only cursors are faster and use the least resources. A While Loop can be used in the case of using a primary key on a table. However, it is advised to avoid the use of a cursor on temp tables.
When you open a cursor, you are fundamentally stacking those lines into memory and locking them, making potential squares. At that point, as you burn through the cursor, you are rolling out improvements to different tables and as yet keeping the greater part of the memory and locks of the cursor open.
All of which can possibly cause execution issues for different clients.
11. Opt for the Use of Table Variable or CTE(Common Table Expression)
Temp Table or Table variable or CTE are commonly used for storing data temporarily in SQL Server
Temp Table: In SQL Server, temporary tables are created at run-time and you can do all the operations which you can do on a normal table. These tables are created inside Tempdb database.
Table Variable: This acts like a variable and exists for a particular batch of query execution. It gets dropped once it comes out of the batch. This is also created in the Tempdb database but not the memory. This also allows you to create a primary key, identity at the time of Table variable declaration but not non-clustered index.
CTE: It is a temporary result set and typically it may be a result of complex sub-query. Unlike a temporary table, its life is limited to the current query. It is defined by using WITH statement. CTE enhances comprehensibility and simplicity in upkeep of complex questions and sub-inquiries. Continuously start CTE with a semicolon.
12. Use Stored Procedure instead of Inline query
If you need a query to execute again and again then create a stored procedure and use it. A stored procedure is compiled when it executes the first time and also creates an execution plan that for subsequent calls to the Stored Procedure because the query processor does not need to create a new plan hence it takes less time to execute.
13. Use Parameterized Query
The SQL Server saves execution plan for parameterized queries. This allows it to be reused on later execution.
14. Avoid Long-Running Transaction
Keep your transactions as short as possible because locks are held during the transaction. Do not forget to roll back or commit the transaction before the session ends.
15. Avoid using Function in WHERE Clauses
It is not a bad thing when a function is used with a select statement because it returns powerful data with each row. In any case, a capacity utilized with a WHERE provision powers SQL Server to do a table sweep to decide the right information.
The above-mentioned tips which are related to the enhancement of SQL server performance are not only the limitations but of course, by using them you can see the major improvement in your query result.
- COVID-19: How We Are Dealing With It as a Company - March 23, 2020
- Agile Testing – The Only Way to Develop Quality Software - February 8, 2019
- How to Perform System Testing Using Various Types Techniques - May 16, 2018
Thanks for sharing this.