
What is Natural Language Processing (NLP)
Natural Language Processing is an automated way to understand analyze human languages and extract information from such data by applying ML algorithms (Machine Learning) and the data content can be text, image, document, audio, and video. Sometimes it is referred to as a field of Artificial Intelligence or computer science to extract the linguistics information from the underlying data. NLP enables machine or computers to drive meaning from natural language or human input.
Jump to Section
Fact about NLP
The world is now connected globally due to the advancement of devices and technology this has resulted in the high volume of digital across the world and has led to a number of challenges in analyzing data including analyzing the tons of data that is generated in the form of text, speech, or any other document.

Applying quantitative analysis of the huge collection of data, handling ambiguities while interpreting data and extracting information. This is where NLP proves useful one of the main target of NLP is to understand various languages process them and extract information from them in NLP full automation can be achieved by modern software libraries, packages, and modules. These software libraries and packages are aware of diverse language and categorized data accordingly which enables better understanding. By using these libraries we can also build analytical models and automate the natural language process with minimum or no human interventions.
Why we need Natural Language Processing?
If we look from the practical side then the huge amount of data available on the internet for example at least 2.5 Billion pages are available and this is a lot of information that is spread all over which is in natural language. So, if a computer has to learn it will have to utilize and understand such expressions which are available in the form of natural language.

There are applications for processing a large number of texts. As you know, a lot of data information is available on the internet, is it possible to classify these text data automatically into categories. For example, all the texts on electricity from school students. Can the computer program really understand the extent, the depth of different texts and identify that well? This is on electricity and these are the contents of this text or suitable for some school children. There are many ways where NLP plays a vital role in,
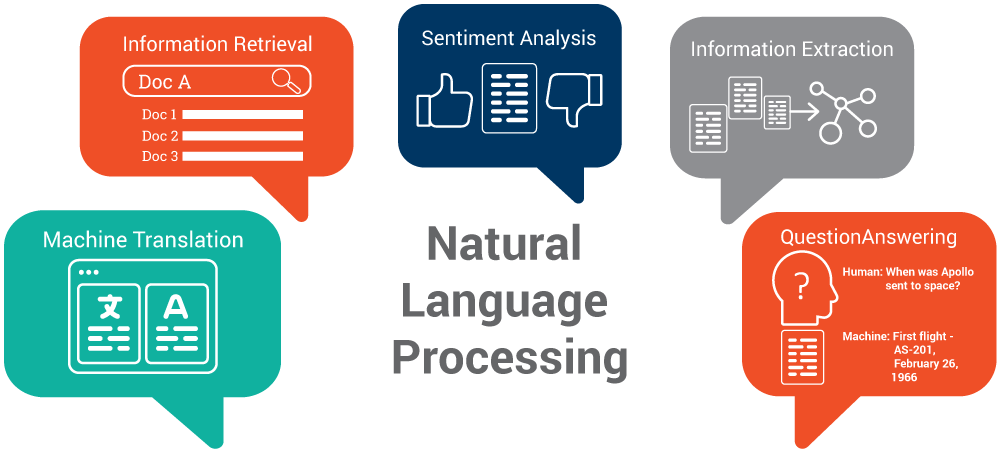
- Index and search for large texts.
- Automatic Translation
- Machine Translation
- Speech Understanding
- Sentiment Analysis
- Understanding Phone conversation
- Information Retrieval
- Automatic summarization (Questioning Answering)
- Knowledge Acquisition
- Text generation/dialogs
Components of NLP
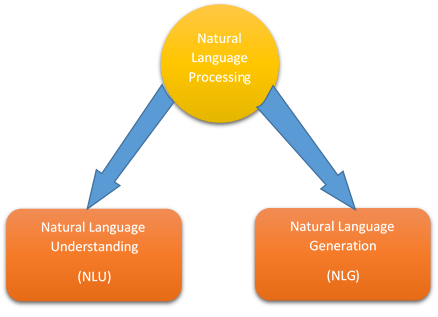
There are two major components of NLP as follows
- Natural Language Understanding (NLU)
- Natural Language Generation (NLG)
NLU
NLU is a part of natural language processing that only deals with machine learning and reading understanding. Language understanding (LU) is considered as no major issue that is the procedure of parsing the input which is more complex and harder than the reverse procedure of assembling output in NLG. Because of unexpected and unknown aspects in the input that need to find out the appropriate semantic and syntactic ways to apply the methods that are predetermined when finalizing language. NLU also uses many types of machine learning algorithms to remove human speech using a structured ontology.
Difficulties in NLU
The natural language contains extreme structure and form. It is obvious that there can be difficulties in the processing levels of natural language understanding as follows.
Lexical ambiguity: − Lexical is kind of primitive level like as word-level. Let’s understand with an example
Treating the actual word “board” as a verb or a noun?
Syntax ambiguity: − A complete sentence or words parse in many ways in this ambiguity. So, let’s understand with an example. “She lifted the small beetle with a green cap.” − Did she really use the cap to lift up the beetle or she lifted that had a green cap?
Referential ambiguity: – It is kind of referral something like as pronouns. Let’s understand with an example, Yami went to Shauri. She stated, “I am tired.” –now, who exactly is tired?. It shows one input meaning but can have different meanings and multiple inputs can have the same meaning.
NLG
Natural language generation is the NLP way of creating natural languages from a single machine representation like a logical form or knowledge base. Psycholinguist always prefers language production value when these representations are compiled as models for different mental representations. It can be said as a translator that can convert big data into an NLG representation. However, the procedure to develop the final language from the compiler is different due to the expressivity of the natural languages system. NLG system has exhausted for a long time but only LG technology has recently become available.
Natural language generation works as the reverse side of NLU. In NLG, the computer system requires to make such decisions that how to conceive a concept into letters or words. For example, systems that create from word or letters and these words or letters do not include grammar rules but they may create a word for a consumer.
NLG systems create text dynamically as in another area of NLP. It can be proceed using explicit top models of language for example grammars and the domain or using statistical models derived by analyzing human-written texts the process to generate text cab be as simple as keeping a list of CAD Computer Aided Design test that is copied and pasted possibly linked with some blue text. The result may be satisfactory and domains like as generators or Horace machines of personalized business words.
The process flow in NLP
Lexical Analysis or Morphological Analysis: It analyzes the complete structure of letters or words in the same language. It is the learning of words that how they are related to each other. Morpheme, it is the tiny but meaningful unit in LA. Lexicon, a collection of multiple words and phrases in a language. Together combine morphological and lexical analysis divides the given corpus into smaller chunks of paragraphs or sentences.
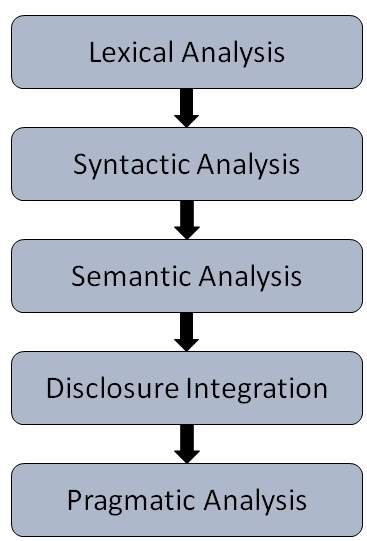
Syntactic Analysis: It is nothing but AI parsing. It provides words analysis in a language for grammar and to arrange them in a manner such that it shows the correct relationship between them. For example,
“A boy plays soccer” – Acceptable
“A soccer plays boy” – Unacceptable
Semantic Analysis: Semantic means it involves the checking of text for its meaningfulness. The semantic analysis draws out the proper meaning and sentence formation from the text. If the meaning of text fits in dictionary meaning then accepted. Otherwise, the semantic analyzer simply rejected the text. For example,
“Hot ice cream” – Unacceptable
Discourse Integration: In general language, the actual meaning of a word or sentence depends upon its previous sentence. Sometimes, you need to read the whole paragraph just to understand the meaning of one sentence. For example,
“John is an author. He has written 3 books last year”
Pragmatic Analysis: It the final step in natural language processing. The analysis of what is said and what is offered? done in the pragmatic analysis. It involves the mapping of language aspects to real-world knowledge.
NLP Terminologies
Natural Language Processing is so important in recent times and it’s time to make you comfortable with NLP terminologies as follows.
Word Boundaries: It determines where each word ends and the other begins.
Tokenization: It’s a technique to split word phrases idioms present in a document.
Stemming: It is a process to map words to their stem or root and it is very useful for finding synonyms and extensively used in search engines.
Tf-idf: This term contains the numerical value which represents the importance of a word that is related to the document or corpus.
Disambiguation: It is a technique to determine the meaning and a sense words context versus intent.
Topic Models: It is a statistical type of model for finding abstract topics which live in documents.
NLP Approaches to Analyze Text Data
These NLP approaches analyze the text data and apply independently but depending on the data type to analyze the text as follows.
Basics text processing: It is a way to analyze text and extract keywords that add the style or basic context of the text for example if the content is religious or fictional.
Categorizing and Tag words: This approach is about finding lexical categories and automatically tagging every word with its class, for example, tag a word using languages such as Chinese, Spanish etc.
Classify Text: This approach will give identify specific features of the text and use them to classify it, for example, classify the text as sports, politics or technology.
Extract Information: It identifies the relationships and entities in a text to extract information in a structured way for example date, money, time and a direction these entities develops relationships with other words available in the text.
Analyze sentence structure: In this approach, it describes the structure of a set of the sentence, for example, find a well-formed or ill-formed sentence structure.
Build feature based Structure: With this approach, we get an insight into grammatical categories of the text document, for example, detect features of texts based on speech tag or some grammar rules.
Analyze the Meaning: This approach performs a quantitative analysis of the given set of data to extract the information, for example, find entities in the text and trying to establish a relationship between them.
Major NLP Libraries
Natural language processing provides an abundance of libraries to apply in analyze the text structure as follows.
1. NLTK: It is a Python-based library for NLP and widely used in the industry to build programming method to work with different human languages.

2. Scikit-Learn: It is another powerful open source Python package and module for NLP it features various algorithms and is designed for operating with other Python libraries like as “numpy” and “acai pie”. This library extracts data using machine learning algorithms. These are some of the essential

Features of Scikit-learn as follows
Built-In Module
It contains built-in modules to load the dataset’s content and categories.
Feature Extraction
It is a way to extract information from the data which can be text or images psych it learns built-in functions and method helps extract features and attributes from text data and image data for the purpose of analysis.
Model Training
It analyzes the content based on particular training in model training. We analyze the content based on particular categories and then train them according to a specific model. Model training can involve supervised or unsupervised models. Supervised models generate the data and find the right answer in this model training the outcome of a new observation.
The unsupervised models response the outcome or the label of the unknown data. The main objective is to understand the complete structure of the data and then identify the pattern in the data. In this type of model training, we find predictors that behave in the same fashion or have familiarity.
3. TextBlob: This library is only used for processing text data. It provides simple APIs for diving into NLP.

4. Spacing: This library provides multiple useful views of textual meaning and linguistic structure.
Conclusion:
In this article, I have explained to you what exactly Natural Language Process is, concept and more about its terminologies. As natural language understanding, device, machines, readability improves, computers will be able to learn fast from the information. I hope this article will help you to understand its basic concept and its terminologies.
However, suggestions or queries are always welcome, so, do write in the comment section. Thank You For Learning!!!
I excel when it comes to making bespoke data dashboards and visualizations that users and clients absolutely love. Sharing about things I enjoy doing is my hobby, whether it's about a project, collaboration, feedback, or just simple how-to guides about visualization.
If you have something to ask or share, I'd love to hear from you!
- Business Intelligence Vs Data Analytics: What’s the Difference? - December 10, 2020
- Effective Ways Data Analytics Helps Improve Business Growth - July 28, 2020
- How the Automotive Industry is Benefitting From Web Scraping - July 23, 2020