
Data Normalization in simple words is a process or a way to maintaining or organizing data in a database. Now, that’s something obvious, but what is the purpose of this whole process? It actually helps to split a large table into different smaller tables. It defines a relationship between these smaller tables that increase the clarity in organizing data.
Normalization helps in decomposing tables to eliminate data redundancy and unwanted characteristics like Insertion, Updation and Deletion Anomalies. Normalizing a data is a multi-step process that puts data in tabular form by eliminating redundant data from the relation tables.
Before having a lot of discussion on Data Normalization, let’s talk about the Database.
So, here the first question arises…
Jump to Section
What is Database?

A database, as the name indicates, is a container that contains the group/package of information. When the information stored in a database then it can be easy to access, manage and update.
Every small portion of information becomes the data in a database. Example, Employee name is a data, Employee Id is a data, and address is a data, height, weight, qualification everything is data. We can say that Data is a kind of raw facts, used to refine some useful information.
When the raw facts/data combined together after proper refinement, it becomes information. Then we can store that processed information in a database in a tabular form.
Why there is a need for data?
This comes to the answer…
To perform some actions to get some result we need data. Before Database, everywhere data was stored in sheets, books & etc and whenever there were any changes in data that will become messy to correct data or there may be chances of data loss.
After Database, it is easy to store data in a proper way which is easy to access in future. If there are any changes in information, we can update/delete them easily.
What kind of data stored in a database?
We store data in a group that is known as a table (identify where data stored and under what name). This saves the time to find particular data in a whole database.
Now let’s move forward…
DATA NORMALIZATION

As stated earlier, normalization is a process or technique to organize data in the database. It is a systematic approach of splitting a table to eliminate different anomalies (like Insertion, Update and Deletion Anamolies) and data redundancy.
When the table normalized that makes database suitable for general-purpose query and free of certain unwanted characteristics that could lead to a loss of data integrity.
Normalization means splitting a table into different small tables which will have less number of attributes in such a way that design of the table must not contain any problem of inserting, deleting, updating anomalies and guarantees no data redundancy.
So, here is the question that…
For which purpose we need to do normalization?
There is two main purpose to use Normalization:
- Ensuring dependencies between data make sense which means data is logically stored.
- Eliminating redundant (useless) data.
Normalization Anomalies
Let’s discuss the issues we face without Normalizing a database:
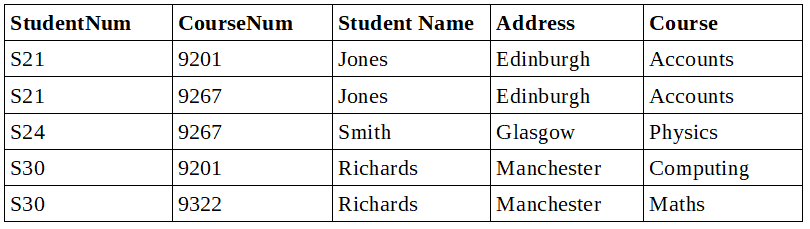
Update Anomaly
An Update Anomaly exists when one or more instances of duplicate data updated, but not all. For e.g., if Jones wants to change the address, you need to update all instances of Jones’s address. If we want to update the address of Jones then we have to update the same in two rows or the data will become inconsistent.
Suppose, the correct address gets updated in one department but not in other. Jones would be having two different addresses, that is not correct and would lead to inconsistent data.
Delete Anomaly
A Delete Anomaly exists when some attributes are lost because of the deletion of some other attributes. For e.g., consider what happens if Student Richards is the last student to leave any of the course, all information about the course will be lost.
Insert Anomaly
It occurs when we try to insert data into the database without the presence of some other attributes. For e.g., we can not add a new course unless we have at least one student enrolled in the course. Suppose a new course added but we would not be able to insert the data into the table if Student Name field doesn’t allow nulls.
We have a different type of data and we need to organize that data accordingly. We can do it with the different form of normalization.
Let’s go ahead and start with these forms…
Normalization Form
To normalize a table we have to use some forms :
- First Normal Form (1NF)
- Second Normal Form (2NF)
- Third Normal Form (3NF)
- Boyce and Codd Normal Form (BCNF)
- Fifth Normal Form (5NF)
There is some more addition of normal forms but we will discuss them later. First, let’s discuss first 3 Normal forms.
First Normal Form

- A table should contain only atomic values that mean every column in a table should have a single value, more than one value should not be stored in a tuple.
- The table should not contain repeating records, all records stored in a table should be unique.
After 1 Normal Form, a table should be:
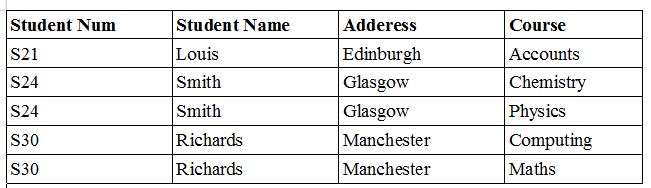
Second Normal Form
A table will be in 2 Normal Form if it satisfies the below conditions :
- A table should be in 1 Normal Form.
- The table must not contain any partial dependency (one of the primary keys determines another attribute or attributes) that means that no non-prime attribute (attributes which are not part of any candidate key) is dependent on any proper subset of any candidate key of the table.
After 2 Normal Form, a table should be:
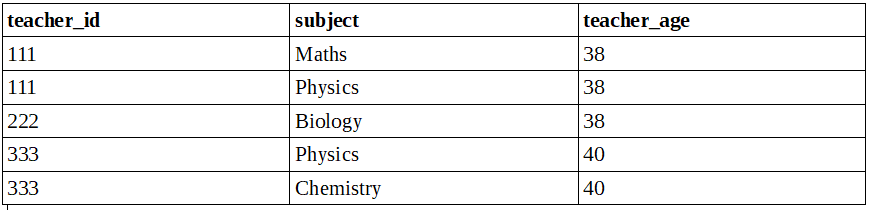
Table 1: Teacher_Details

Table 2: Teacher_Subjects
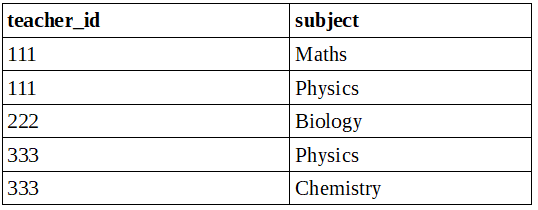
Third Normal Form
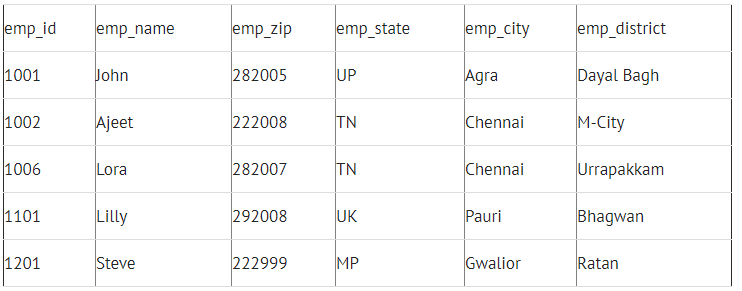
A table will be in 3 Normal Form if it satisfies the below conditions:
- A table should be in 2 Normal Form.
- The table should have a transitive functional dependency ( when a non-key attribute determines another attribute).
There are two advantages of removing transitive dependency,
- Achieved data integrity.
- It reduces the amount of data duplication.
After 3 Normal Form, a table should be:
Table 1: Employee_Details
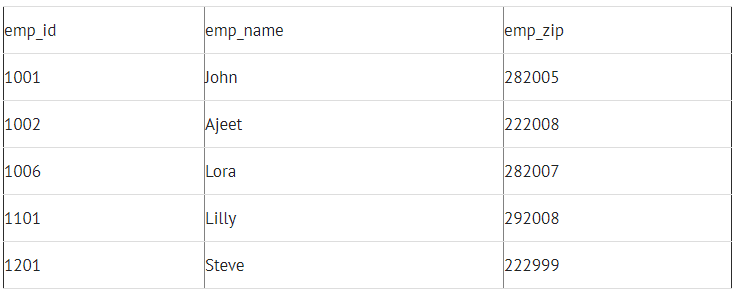
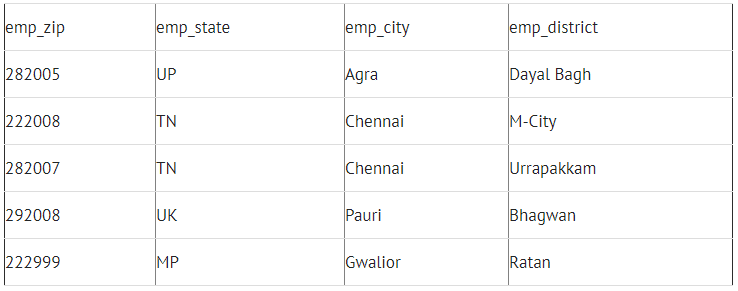
Table 1: Employee_Zip_Details
Conclusion
I think now it’s clear that whatever data you store in a database but it should be well structured. With the normalization, we can easily maintain our data in an effective manner and can make a relationship between them that helps to reduce data redundancy. It helps to achieve ACID properties (Data Atomicity, Data Consistency, Data Integrity, & Data Durability).
In Normalization, Functional dependencies are a very important component of the normalized data process. Most of the time, we normalize database up to the third normal forms but we can go for other normal forms as well. I would like to discuss them later.
- Difference Between SQL and MySQL - April 14, 2020
- How to work with Subquery in Data Mining - March 23, 2018
- How to use browser features of Javascript? - March 9, 2018
Good job.. 🙂