
Nowadays, big data applications have become so popular that one can find an enormous amount of information available on the Internet related to Big data. The popularity of this trending topic is touching onto new heights of success day-by-day. This fact is stated clearly on the Google Trends (refer below):
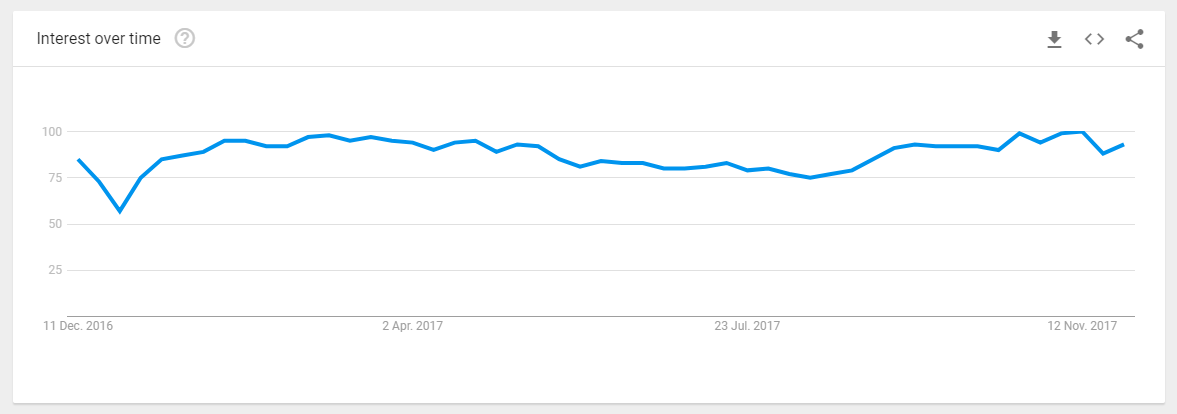
And in case you still have doubts, refer to more proofs on Big Data application popularity and impact over today business, you can go through different Stats of BIG DATA.
The growth of a big data application extremely dependent on business rules, customer requirement, customer basic information, and updated product information. There are many facts that affect the success of Big Data application. One of the most important facts is QUALITY and good quality is maintained by testing techniques followed by testers of the BIG DATA APPLICATION.
Before, coming on the testing side of a Big Data Application, let’s have a look at basics of a big data applications.
Jump to Section
Big Data Applications: The Basics
Big Data Applications are applications, which rapidly process a huge amount of different kind of data to fulfill the business requirement. A Big data application basically consists of three things:
- Very large volume of data
- Number of data types
- Fast processing speed
Volume of Data
A traditional database is not built to handle a large volume of data. Whenever data is getting increased in these systems, it is required to have more shared storage systems. Maintenance of these storage systems causes increase maintenance cost. Apart from maintenance cost, these systems can handle maximum data till petabytes (PB) of information that we can say starting amount of data processed in Big data applications.
Now, you must be thinking of how that much data is getting generated in Big Data application, so there are few examples of the most common activities happen per minute over the Internet that act as data sources:
- 1500 blog posts
- 60 blog
- 600 new videos are uploaded to youtube
- 70 domains are registered
- 40 questions asked on yahoo are answered and 100 + questions answered on answers.com
- 1300 iPhone applications are downloaded every minute
- 694445 searches are made on Google every minute
- 320 accounts are created on Twitter and more than 98000 tweets
(Source: data-flair.training/blogs/big-data-applications-various-domains/)
A Big Data application can process petabytes (1,024 terabytes) to exabytes (1,024 petabytes) and more. These applications collect data from different sources such as Customer Contact Center, Market research and social Networking sites. Below are some big data stats of popular Websites:
- Twitter: More than 90 million tweets/day
- eBay: Two storage unit for handling 7.5 petabytes and 40PB respectively
- Walmart: Approx. >1 million transactions/ hour by customers
Types of Data
Data processed in big data application can be either structured data or unstructured data. Structured data is generally handled by Relational Data Base Management System and most common example of these data are text, numbers and date etc. These are very common for all type of application but unstructured data refer to the different types of data such as Files, video, audio, image and many more.
Unstructured data can not be managed by traditional DB system because that data needs to be processed to quickly but the traditional system is not so quick to do so. Moreover, the quantity of data in Big data application is not predictable. A big data application can process generally of petabytes, Exabyte’s amount of data. A successful big data application must be capable to process that a large amount of data within seconds and that cannot be possible for a traditional DB system.
Processing of Data
Traditional Application with traditional DB consists of centralized DB architecture. In this architecture, processing is done by a single computer system. Maintenance of this architecture is also very high. On the other hand, Big data application uses a distributed database to handle a large amount of data.
A distributed database architecture helps to fast processing of data with use of several small processing units. Maintenance of small processing units is not so expensive which causes low maintenance cost of a big data application. Although usage of processing unit doesn’t include high computation power, yes, it provides a very good performance of a large amount of data and that is the backbone of any big data application.
Real Time Examples of Big Data Application
A shopping site is a very common and real-time example of big data application. A shopping site must have information of the visitor by capturing its current location (region, country) on the basis of that information various products can be suggested to that visitor.
The application should also capture a visitor’s all visited item to manage its review history and show data in its recently viewed item section. On the basis of visitor’s area of interest, many products can be suggested to that visitor.
Apart from shopping sites, there is a number of applications such as healthcare application, Finance application, Crime Detection application, Social Networking sites etc.
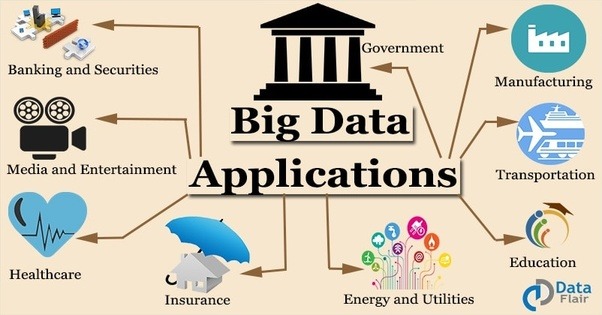
Hurdles Faced In Testing Big Data Application
Whenever we are talking about the testing of an application, then we have a certain level of quality of that application in our mind. For maintaining the quality of a big data application, it is mandatory to work around 3Vs of Big Data application. Means, a tester should be able to:
- Volume: Verify that data collected from various data sources are correct
- Variety: Verify that type of data collected is correct
- Velocity: Verify that data is correctly processed for the required business or not
In simple words, in a Big Data Application, first data is collected from a number of sources then distributed among different processing units and then get integrated after applying data validation rules. For that complete process, there is a number of challenges for testing a big data application, few of them are:
- Prompt Collection of Data – In big data application, lots of data instantaneously come from a number of data sources. Type of data from different sources is different. The application has to first process these sets of data in the processable form. For this, the tester should be able to predict all possible sets of data that can be received from different sources so that he/she can apply decision-making techniques to get instant solution. These decision-making techniques and sets of virtual data have a great impact on quality of the application.
- Rapid Integration of information – As big data application get different types of data, so it is essential to maintain consistency and accuracy of data while doing the integration of all information for further processing. Hence, integration techniques should also be known to testers so that they can analyze data that need to be processed through the programming model of the big data application.
- Quick Deployment – To maintain promptness and responsiveness of a big data application, it is mandatory to manage the instant deployment of a processed set of data. The tester should have knowledge of that deployment process also so that they can identify the probable loop-holes of the application that can occur due to deployment.
Strategy to Test a Big Data Applications
Testing of a big data application is a little bit different from a simple software. While talking about testing, we cover two aspects of a software Non-functional and Functional.
For non-functional testing such as Performance, and Security, there are a number of tools available in the market. For functional testing, we mainly focus on all functionality of that software. However, we should not focus on functionality only but also an emphasis on its other areas like all sources where data come from, its processing unit, i.e., Map Reduce and Output systems where processed data need to be displayed.
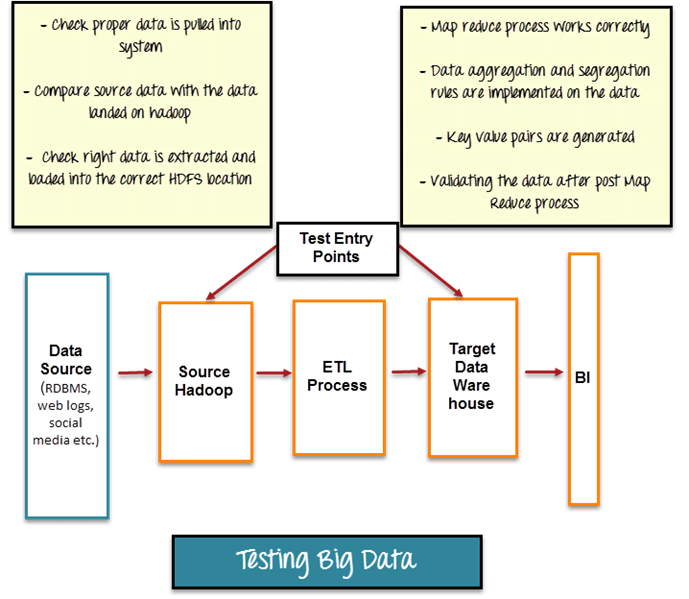
Functional Testing Of A Big Data Application
For testing a Big Data applications, a tester must have knowledge of different fields such as Database testing, Integration testing, Artificial Intelligence, clustering methods, State-Transition Testing and ETL (Extract-Transform-Load) techniques. QA needs to perform functional and non-functional testing in Big data application too. We can basically divide functional testing of a big data application into three phases:
1. Data Validation
In Big Data Application, data is collected from various sources and form of data is not structured, so it is mandatory to check data, which need to be processed. Quality of data is very important in big data application and maintaining data quality includes accuracy, consistency and validity of data. Data Validation testing is generally known as Pre-Hadoop testing. The most common tool used for data validation is “Talend”. Basic steps in this testing are:
- Verifying correctness of data coming from various sources
- Matching source data and data pushing to Hadoop system
- Validating that extracted data is getting push to correct Hadoop location
2. Logic Validation
In this phase, the tester needs to do testing of basic business logic, i.e., Map Reduce process applied to data. Map Reduce is a programming framework, which allows processing a large amount of data in a distributed environment using different machines called Node. So in this phase, the tester has to do testing of logic validation on all nodes. Moreover, it is required to validate each logic on which data get either segregated or aggregated.
3. Output Validation
In this phase, the tester needs to check data before it moves to data wares house. Data warehouse generally stores all processed data that need to be displayed in different places in form of charts, reports, Web, Business Intelligence tools. Testing in this phase is generally known as Post-Hadoop testing, where tester needs to check that:
- All processed data is successfully stored in Data warehouse or not.
- Data is getting loaded from data warehouse to the target system or not.
Steps For Performance Testing Of Big Data Applications
It has been already stated in above paragraphs that processing of large data in a very less time is the core of the big data application. Hence, performance testing is another important quality factor for Big Data Applications. Performance of a big data application dependent on a number of parameters of different processing units such as concurrency, cache time, programming model effectiveness and message-transitions among all processing units.
To do performance testing, there are following steps:
- Prepare test data using a big cluster of data.
- Test Data cluster should contain all kinds of data that is being processed in the big data application.
- Specify the most expected workloads.
- Develop test scripts for most common scenarios.
- Run the test scripts and analyze the results.
- Reconfigure the workload and re-execute the scripts, in case results are not met expectation.
I hope the understanding of Big Data QA is in a broad light now. However, for further queries, you can place your valuable comments in the comments section below!
I excel when it comes to making bespoke data dashboards and visualizations that users and clients absolutely love. Sharing about things I enjoy doing is my hobby, whether it's about a project, collaboration, feedback, or just simple how-to guides about visualization.
If you have something to ask or share, I'd love to hear from you!
- Business Intelligence Vs Data Analytics: What’s the Difference? - December 10, 2020
- Effective Ways Data Analytics Helps Improve Business Growth - July 28, 2020
- How the Automotive Industry is Benefitting From Web Scraping - July 23, 2020
Very well explained