
This article is the second part of our series on scraping website using HTML Agility-Pack. Having tackled the cover and contents page in the previous article, we’re now ready to put the main content. Let’s start off with:
Jump to Section
HTML Selectors
Selectors allow you to select HTML node from HTML document.
HTML Selector Methods
SelectNodes() : Collect a bunch of nodes matching the X-path expression.
SelectSingleNode(String): Collect the first Xml-Node that matching the X-Path expression.
SelectNodes Method
Selects a list of nodes matching the HtmlAgilityPack.HtmlNode.XPath expression.
Parameters: xpath(The XPath expression.)
Returns: An HtmlAgilityPack.HtmlNodeCollection containing a collection of nodes matching the HtmlAgilityPack. HtmlNode.XPath query, or null if no node matched the X-Path expression.
Examples:
(i) The following example selects the first node matching the X-Path expression using SelectNodes method.
var htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(html);
string name = htmlDoc.DocumentNode.SelectNodes("//td/input").First().Attributes["value"].Value;
(ii) The following example selects all nodes which are matching the XPath expression.
var htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(html);
var htmlNodes = htmlDoc.DocumentNode.SelectNodes("//td/input");
SelectSingleNode Method
Selects first HtmlNode matching the HtmlAgilityPack.HtmlNode.XPath expression.
Parameters: xpath(The X-Path expression. May not be null.)
Returns: The first Node that matches the X-Path query or a null reference if no matching node was found.
Example:
The following example selects the first node matching the X-Path expression using SelectNodes method.
var htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(html);
string name = htmlDoc.DocumentNode.SelectSingleNode("//td/input").Attributes["value"].Value;

HTML Manipulation
Manipulation allows you to cross HTML node.
HTML Manipulation Properties
InnerHtml: Gets or Sets the HTML within the start and end tags of the object.
InnerText: Gets the text between the start and end tags of the object.
OuterHtml: Gets the object and its content in HTML.
ParentNode: Gets the top most node of this node (for nodes that can have parents).
InnerHtml
public virtual string InnerHtml { get; set; } :-
Gets or Sets the HTML between the start and end tags of the object. InnerHtml is a member of HtmlAgilityPack.HtmlNode.
Example:
var htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(html);
var htmlNodes =htmlDoc.DocumentNode.SelectNodes("//body/h1");
foreach (var node in htmlNodes)
{
Console.WriteLine(node.InnerHtml);
}
InnerText
public virtual string InnerText { get; } :-
Gets the text between the start and end tags of the object. InnerText is a member of HtmlAgilityPack.HtmlNode .
Example:
var htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(html);
var htmlNodes = htmlDoc.DocumentNode.SelectNodes("//body/h1");
foreach (var node in htmlNodes)
{
Console.WriteLine(node.InnerText);
}
OuterHtml
public virtual string OuterHtml { get; } :-
Gets the object and its content in HTML. OuterHtml is a component of HtmlAgilityPack.HtmlNode.
Example:
var htmlDoc = new HtmlDocument();
var htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(html);
var htmlNodes = htmlDoc.DocumentNode.SelectNodes("//body/h1");
foreach (var node in htmlNodes)
{
Console.WriteLine(node.OuterHtml);
}
HTML Manipulation Methods
AppendChild(): Combine the specified node to the end of the children’s list of this node.
AppendChildren(): Merge the identified node to the end of the list of children of this node.
Clone(): Generate the identical of the node.
CloneNode(Boolean): Generate an identical of the node.
CloneNode(String): Generate an identical of the node and modify its name at the same time.
CloneNode(String, Boolean): Generate an identical of the node and modify its name at the same time.
CopyFrom(HtmlNode): Make an identical of the node and the sub-tree under it.
CopyFrom(HtmlNode, Boolean): Make a copy of the node.
CreateNode(): Make a HTML node from a string representing literal HTML.
InsertAfter(): Inserts the enumerated node immediately after the enumerated reference node.
InsertBefore: Inserts the enumerated node immediately before the enumerated reference node.
PrependChild: Adds the enumerated node to the start of the children’s list of this node.
PrependChildren: Merge the enumerated node list to the start of the list of children of this node.
Remove: Discard node from the main collection.
RemoveAll: Discard all the children and/or attributes of the present node.
RemoveAllChildren: Delete all the children of the present node.
RemoveChild(HtmlNode): Remove the enumerated child node.
RemoveChild(HtmlNode, Boolean): Removes the enumerated child node.
ReplaceChild(): Replaces the child node oldChild with newChild node.
HTML Traversing
Traversing allow you to traverse through HTML node.
HTML Traversing Properties
ChildNodes: Gets all the children of the node.
FirstChild: Gets the first child of the node.
LastChild: Obtains the final child of the node.
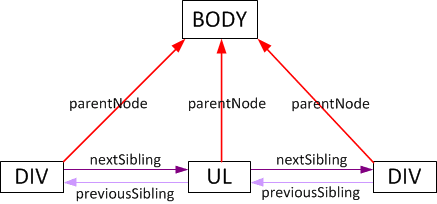
NextSibling: Obtain the node instantly following this element.
ParentNode: Obtain the upper node of this node (for nodes that can have parents).
ChildNodes
Example:
using system;
using system.xml;
using htmlAgelityPack;
public class Program
{
public static void Main()
{
var html=@"<body>
<h1>This is<b>bold</b>heading</h1>
<p>This is <u>underline</u>paragraph</p>
</body>";
var htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(html);
var htmlBody = htmlDoc.DocumentNode.SelectSingleNodes("//body");
HtmlNodeCollection childNodes = htmlBody.ChildNodes;
foreach (var node in childNodes )
{
if(node.NodeType == HtmlNodeType.Element)
{
Console.WriteLine(node.OuterHtml);
}
}
}
}
Output:
<h1>This is<b>bold</b>heading</h1> <p>This is <u>underline</u>paragraph</p>
FirstChild
Example:
using system;
using system.xml;
using htmlAgelityPack;
public class Program
{
public static void Main()
{
var html=@"<body>
<h1>This is<b>bold</b>heading</h1>
<p>This is <u>underline</u>paragraph</p>
</body>";
var htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(html);
var htmlBody = htmlDoc.DocumentNode.SelectSingleNodes("//body");
HtmlNodeCollection firstChild= htmlBody.FirstChild;
Console.WriteLine(firstChild.OuterHtml);
}
}
Output:
<h1>This is<b>bold</b>heading</h1>
LastChild
Example:
using system;
using system.xml;
using htmlAgelityPack;
public class Program
{
public static void Main()
{
var html=@"<body>
<h1>This is<b>bold</b>heading</h1>
<p>This is <u>underline</u>paragraph</p>
</body>";
var htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(html);
var htmlBody = htmlDoc.DocumentNode.SelectSingleNodes("//body");
HtmlNodeCollection lastChild= htmlBody.LastChild;
Console.WriteLine(lastChild.OuterHtml);
}
}
Output:
<p>This is <u>underline</u>paragraph</p>
NextSibling
Example:
using system;
using system;
using system.xml;
using htmlAgelityPack;
public class Program
{
public static void Main()
{
var html=@"<body>
<h1>This is<b>bold</b>heading</h1>
<p>This is <u>underline</u>paragraph</p>
<h2>This is<i>italic</i>heading</h2>
<h2>This is new heading</h2>
</body>";
var htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(html);
var node = htmlDoc.DocumentNode.SelectSingleNodes("//body/h1");
HtmlNode sibling = node.NextSibling;
while(sibling != null)
{
if(sibling.NodeType == HtmlNodeType.Element)
{
Console.WriteLine(sibling.OuterHtml);
sibling = sibling.NextSibling;
}
}
}
}
Output:
<p>This is <u>underline</u>paragraph</p> <h2>This is<i>italic</i>heading</h2> <h2>This is new heading</h2>
HTML Traversing Methods
Ancestors(): Gets all the ancestor of the node.
Ancestors(String): Gets ancestors with matching the name.
AncestorsAndSelf(): Gets all anscestor nodes and the current node.
AncestorsAndSelf(String): Gets all ancestor nodes and the current node with matching the name.
DescendantNodes: Obtains all Descendant nodes for this node and each of child nodes.
Descendants(): Obtain all Descendant nodes in enumerated list.
Descendants(String): Get all descendant nodes with matching the name.
DescendantsAndSelf(): Returns a group of all descendant nodes of this element, in document order.
DescendantsAndSelf(String): Gets all descendant nodes including this node.
Element: Gets first generation child node matching name.
Elements: Gets matching first generation child nodes matching the name.
HTML Writer
Save HtmlDocument & Write HtmlNode.
HTML Writer Methods (HtmlDocument)
Save(Stream): Saves the HTML document to the specified stream.
Save(StreamWriter): Saves the HTML document to the specified StreamWriter.
Save(TextWriter): Reserves the HTML document to the enumerated TextWriter.
Save(String): Reserves the mixed document to the enumerated file.
Save(XmlWriter): Reserves the HTML document to the enumerated XmlWriter.
Save(Stream, Encoding): Watch over the HTML document to the enumerated stream.
Save(String, Encoding): Watch over the mixed document to the enumerated file.
HTML Writer Methods (HtmlNode)
WriteContentTo(): Saves all the children of the node to a string.
WriteContentTo(TextWriter): Reserves all the children of the node to the enumerated TextWriter.
WriteTo(): Reserves the current node to a string.
WriteTo(TextWriter): Reserves the current node to the enumerated TextWriter.
WriteTo(XmlWriter): Reserves the current node to the enumerated XmlWriter.
HTML Utilities
HTML Utilities Methods (HtmlDocument)
DetectEncoding(Stream): Find out the encoding of an HTML stream.
DetectEncoding(TextReader): Find out the encoding of an HTML text provided on a TextReader.
DetectEncoding(String): Find out the encoding of an HTML file.
DetectEncodingAndLoad(String): Find out the encoding of an HTML document from a file first, and then loads the file.
DetectEncodingAndLoad(String, Boolean): Find out the encoding of an HTML document from a file first, and then loads the file.
HTML Attributes
HTML Attributes Methods
Add(HtmlAttribute): Adds supplied item to collection.
Add(String, String): Adds a new attribute to the collection with the given values.
Append(String): Creates and inserts a new attribute as the last attribute in the collection.
Append(HtmlAttribute): Inserts the specified attribute as the last attribute in the collection.
Append(String, string): Creates and inserts a new attribute as the last attribute in the collection.
Remove(): Removes all attributes from the collection.
Remove(String): Removes an attribute from the list, using its name. If there are more than one attributes with this name, they will all be removed.
Remove(HtmlAttribute): Removes a given attribute from the list.
RemoveAll(): Remove all attributes in the list.
RemoveAt(): Removes the attribute at the specified index.
SetAttributeValue(): Sets the value of an attribute, adds an attribute, or removes an attribute. If the attribute is not found, it will be created automatically.
I have covered a lot of ground in very little code which I hope this post shows us how to effectively parse HTML documents in C# and further impresses on you the power of this library!
- LinkedIn Scraper | LinkedIn Data Extractor Software Tool - February 22, 2021
- Is Web Scraping Legal? - February 15, 2021
- What Is Data Scraping? - February 10, 2021
Hello Kumar, excellent blog, and your html agility pack articles will be very useful on my next project. I have a question… How can I access a website that required login, and continue navigating and scraping a site? Thanks!