
If you have decided to click on this blog, then you must be a QA person. Isn’t it? So, what are you working on – Smoke, Sanity and Regression Testing??? Be it whatever, the baseline is almost same!!! You must be thinking along the same lines, but just to clear out the misty cloud of your thought process Smoke, Sanity and Regression are totally different!
So I prodded myself to write a blog on Smoke, Sanity and Regression Testing to clear out the confusion between them. Let’s proceed ahead to widen up our knowledge…
Every tester performs smoke and sanity testing in their organizations. Both testings create a big skeptical when a QA person performs Smoke, Sanity and Regression Testing. And it’s also a big task to discrete your test cases into the Smoke, Sanity and Regression tests, suiting on the basis of priority. We can also say Smoke and Sanity testing are the most misunderstood topics in testing.
Jump to Section
Regression Testing
Regression testing is the type of testing, which is used to ensure that changes (these may be bug fixes or any changes in the requirement) are not affecting the other functionalities of the application. Other functionalities which were developed previously and there is no change in these functionalities. Regression test cases are executed after some enhancements in the requirement or bug fixes.
Once the re-testing is completed of the module in which changes are being made, all modules of the application require testing thoroughly, this is called regression testing.
Whenever the defect fixes are done by the developer, a bunch of test cases that need to be run to verify the defect fixes. The tester needs to analyze the impacted areas to find out what areas may get impacted due to those bug fixes. Based on the analysis, some more test cases are needed to be selected to take care of the impacted functionalities.
When testers need to perform the regression testing:
- When the code is modified according to the change requirement.
- Bug fixing.
- Some new features are added to the application.
Smoke Testing

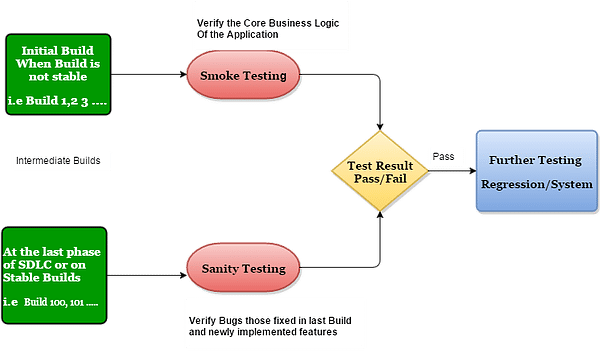
Smoke is the ‘Build Verification Testing’, How? It is performed by developers before releasing the build to the QA team. After releasing the build to the QA team, it is performed by QA whether to accept the build to know that build is ready for further testing or not. The smoke tests might be run before deciding to proceed with deep testing.
Let say, there is a new application like ‘Employee Details’ which has 10 modules. Among them, the tester needs to navigate to all the modules (means critical functionality of all the modules are working fine) to ensure that software build is ready for further testing or QA need to reject. The main purpose of smoke testing is to show the stability of the application.
When testers need to perform the smoke testing:
- QA gets the new build from the developer.
- When a new module added to the current application.
Sanity Testing
There are lots of definitions of Sanity Testing, but here I am sharing my experience, let’s see your build is ready to go live, what will you do? Will you execute all test cases? Of course not!
Sanity Testing will be run to the stable builds, it gets executed to check whether your build is ready to deploy in the production environment or the UAT environment or Sometimes, Sanity Testing is performed for those builds which have gone through many regression tests and has come after a little change in code.
In this case, we normally do the short testing not deep testing of functionality for which this new change has come.
When testers need to perform the sanity testing:
- When we get build after many regressions even if minor change.
- Bug fixing.
- Just before the deployment of the production.
Differentiation of Smoke, Sanity and Regression Testing on the basis of Prioritization of test cases
If your manager asks you to make the separate test cases of sanity, smoke, regression from the big bunch of test cases. Will you categorize your test cases manually? No, you don’t need to make more effort. Here is the easiest way to separate test cases by prioritizing the test cases!
Prioritizing the test cases depends on the critical, frequently used functionality, business impact. Separation of test cases based on priority will reduce the test suit. These test cases can be classified into three categories:
Priority-Zero:
Sanity test cases can be created on the basis of basic functionality and are run for accepting the build for further testing. These are also run when a project goes through major changes. These test cases deliver a very high project value to both development teams and to customers.
Priority-One:
These test cases use the basic and normal functionality and these test cases deliver high project value to both development teams and customers.
Priority-Two:
These test cases deliver high project value and are executed as a part of a software testing life cycle. These test cases will be selected for regression on requirement basis.
Software Builds
Have you noticed a word “Build” and Build which is being used above in Regression, Smoke and Sanity Testing in since the start of this article? This word “Build” can create a question and big confusion, even they can get irritatingly too! What is build? So, let me write a few lines for the definition of Builds.
A software is made up of multiple code files and when these files are separate its compilation seems easy but Before executing the program, the compilation of all files together is very tedious. So developers make executable file by integrating all these files. These executable files are known as the Software Builds.
Summarizing
A subset of the regression test cases can be set as a smoke test. A smoke test is a number of test cases that establish that the application is stable and all major functionality is available and works. Smoke tests are often automated, and the selection of the test case is broad in scope. The smoke tests may be run before deciding to proceed with further testing. Time of dedicate resources should not be wasted if the application is very unstable.
I hope you all are clear about Smoke, Sanity and Regression testing!
- COVID-19: How We Are Dealing With It as a Company - March 23, 2020
- Agile Testing – The Only Way to Develop Quality Software - February 8, 2019
- How to Perform System Testing Using Various Types Techniques - May 16, 2018