
Hello readers, here I have come with another article “Steps you need to take before scraping a website“. In this session, I will tell you from scratch as what points you need to remember.
So, let’s start Scraping.
Jump to Section
What is Scraping?
Scraping or Web scraping defines the extraction of data in terms of HTML code from the website. Scraping a website is related to software techniques from where you can run your software and extract the output. Scraping contains multiple varieties in web scraping because you can even scrape data from static or dynamic websites. Web scraping transforms the unstructured data into legal structured data. Here, unstructured data looks like an HTML (Hyper Text Markup Language) format and structured data looks like in CSV, Excel, JSON, and Database Spreadsheets etc. In this article, I will discuss more checkpoints before scraping a website.
Steps Before Scraping a website
Step 1: Think Like A Machine, Not Human
Basically, A website is a mixture of HTML code. Both static or dynamic websites contain their HTML code on every web page of the websites. For this reason, use a scraping tool for extracting the data from the webpage. The script will set the machine. Whenever you are required to scrape code from the website, you can do it easily by clicking a single button on your scraping tool.
But this will not work every time when you scrape, because dynamic sites can be changed at any moment and your scraping tool cannot understand what changes have occurred on the website. But a human brain can recognize on the website where and what new changes occurred.
Therefore, you will need to rewrite your HTML code or edit your code in your script of a web page. It may take some hours for doing changes. To solve this problem, developers have now been taught to use scraping tools to perceive as a human brain or human understanding does. These amazing steps were taken by developers called “Visualization Abstraction”. This visual abstraction applies the machine learning code to enhance the machine to extract the data from the web page as people do.
Step 2: Set up your Scraping Tool
You can scrape a website with the help of any programming language. But I recommend, use Python during the web scraping. Why Python? Because of its code simplicity by using feature “BeautifulSoup”. By using this feature you can easily capture or extract the data in less time as compared to any other programming language. It also contains a few lines of codes in Python while scraping a website and its standard library packages make the code easy to write and easy to understand. Just write in Python
pip install Beautifulsoup4
Basically, BeautifulSoup analyzes the data in terms of HTML code on the web page. It is now updated as “Beautifulsoup4”. Now, “pip” is a Python module which runs the line of command we provide.
Step 3: Send URL request
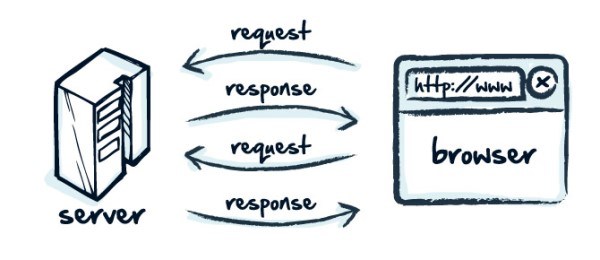
When you set up the script code, send a URL request to the website that you want to scrape. Because, if you do not send a URL request or if you forget to send by chance then data will not be downloaded. It will throw an error on the screen. Before sending a request, clear your browsing history, cache memory, cookies etc. Sometimes you scrape data from the website, surely it will download the data. But it may not take guarantee that extracted data will be downloaded correctly or not. Sometimes it downloads different data which you do not need. So, first make your history clear.
Step 4: Do not send URLs to request parallelly
Do not send URL request parallelly or do not send too many requests on the website. When you send a URL request to the website which contains your system IP address. If you send request parallelly one by one then the website will catch your same IP address which leads you to “Denial Service Attack” on their website. As a result, a tough action can be taken by the website owner or your IP address can be blocked. So, make your move wisely. Hide your proxy or you can even change it from time to time.
Step 5: Make your crawling slow and Treat website nicely

To treat the website nicely, use a throttling function that controls the crawling speed automatically on the spider load and website. You can even adjust the spider to a neutral speed after a trail runs. If you run faster the crawl you get the worst result. You have to add some libraries after crawling a minimum number of web pages and choose the less number of a consistent request if possible. Spider looks good for every web scraper when you use these techniques.
Step 6: Download requested data and Run you Script Code

In this step, you will download data of all URLs. Scraping tool will automatically fetch the data from the website. The requested data will convert from unstructured to the structured dataset in a particular format. I would like to recommend that run your code again after you make any change in the script.
Note: Try to download data in small amount URLs link. Do not send downloading request for all URLs together.
Step 7: Split Scraping data into different phase
It will make a way for you if you split scraping data into smaller phase. Let’s understand with a small example. When you choose a website for scraping then divide the website into two phases. In the first phase, collect all of the links to the page that you want to extract data. In the second phase, download the webpages to scrape content.
Step 8: Storage for URL
This is a very important point to store a list of URLs. Let’s assume you downloaded data up to 75% and after that, you’re scraping got failed or stopped for some technical reason then what would you do to finish rest of the 25% data. If it happens definitely it will waste your much time. So, make permanent URLs list in a database.
Conclusion
I hope you enjoyed my article. This is very important for everyone who wants to scrape a website. These are the main checkpoints which you have to think before going to scrape a website. If you follow the process of web scraping then you can get easily what you want, if you not then you may face some big problems. So, make you move nicely.
However, do write your suggestions or query to me in the comment section.
Thank You for reading!!!
- LinkedIn Scraper | LinkedIn Data Extractor Software Tool - February 22, 2021
- Is Web Scraping Legal? - February 15, 2021
- What Is Data Scraping? - February 10, 2021