Jump to Section
Introduction
Today the term big data is not new to us. Currently, we are living in a data-oriented world. To process that amount of data there are numerous technologies in the market and it can be hectic to decide which one to choose.
This is the reason I thought of writing this post. With the help of this blog, I am trying to give you the glimpse of one of the big data Technology Hadoop.
What is Big Data?
Generally, Big data term is originated from 3V’s terminology. But according to IBM definition of big data it consists of 4V’s.
- Volume
- Variety
- Velocity
- Veracity (4thv By IBM).
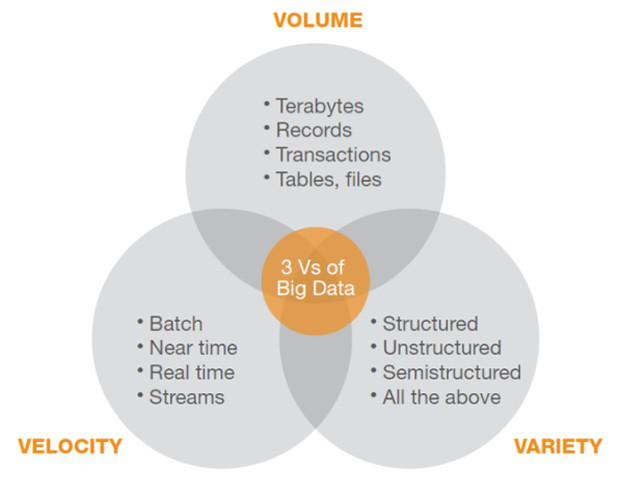
- Volume: – Big data implies huge volumes of data. According to IDC7 Zettabytes of data exist in the digital universe until Feb 2017. From this figure, you can estimate the amount of data we are generating every second.
- Variety:- As the heading indicates, the types of data we are generating like in the form of emails, photos, videos, PDFs, audio, etc. Which is unstructured or semi-structured in nature.
- Velocity:-Big Data Velocity deals with the pace at which data is generating from the sources like social media, Sensors devices, CCTV video recording and many more sources. Last year’s report found that more than 3.5 million text messages were sent every minute in the world. Now, it’s around 15.2 million texts, a 334 percent increase in 2017.
- Veracity: – Data which is inconsistence or approximate but as important as 3V’s for analysis part. For eg Facebook data which consist of photos, videos, likes and more.
Categorization of Data:-
- Structured
- Unstructured
- Semi-structured
Structured: –
The data that can be stored and processed in the form of fixed format is known as a structured data. Our traditional existing database is the best example of it RDBMS (Relational Database Management System).
Unstructured: –
The data which is heterogeneous in nature consist of different sources and the representation of data is different from structure data is known as unstructured data.
For example, screenshot contains image, information in the form of text and links to Articles.
Semi-Unstructured: –
Semi-structured data can contain both forms of data. Semi-structured data in structured form but it is actually not fully structured like in the form of rows and columns. For e.g. a Jason dataset

Why Big Data Analytics is Important?
Big data analytics helps organizations from their data and use it to predict new opportunities. That can lead to smarter business moves and efficient operations and less time consumption and high profits and also customers satisfaction.
What we do not need is big data; we required data which leads to some actionable and useful data. Below are some of the examples how big data is used to solve challenges for different industries.
Retail and Wholesale trade
Today e-commerce industry has gathered a lot of data over time. This data, derived from customer personal data, e-mails, contact numbers, Credit card details etc. are not being used enough to improve customer experiences on the whole.
Applications of big data in the Retail industry
Customers data gathered from loyalty card data, Point of sale, inventory management, transactional data. Companies are using that data to reduce following points.
- Optimizing staff management through data from shopping patterns, local events and more.
- Supply Chain Management
- Reduce fraud.
- Dynamic Price and Offers
- Timely analysis of inventory.
- Predictive Analytics
- Market Basket Analysis.
E-commerce companies also considering social media data has a lot of potentials to use and continues to be crucial in coming days. Social media is used for new customer, customer retention, promotion of products, and more.
Big Data Tools: –
Right now there are plenty of new technologies or tools are available in the market which is dealing with processing and analyzing the huge amount of data is as follows.
- Apache Hadoop
- Hive
- Pig
- Elastic search
- MongoDB
- R-Programming
- Casandra
What is Hadoop?
Hadoop is an open-source tool from Apache Software Foundation. Open source project means it is freely available and we can even change its functionality in the source code as per the requirements. It provides an efficient framework for running jobs on multiple nodes of clusters. Cluster means a group of systems connected via LAN and running simultaneously. Apache Hadoop provides parallel processing of data.
Apache Hadoop is an open source framework written in Java. The default programming language for Hadoop is Java, but that does not mean you cannot use any other programming language to communicate with Hadoop. You can code in C, C++, Perl, Python, R etc.
Big Data and Hadoop effectively process a large amount of data on a cluster of (commodity hardware) Commodity hardware is the low-end hardware; cheap devices which are very economical.
Hadoop can be set up on a single machine which is also called as the pseudo-distributed mode or Vanilla cluster, but it displays its efficiency with a cluster of machines. We can add thousand nodes or computer within cluster which is known as multi-node cluster.
Hadoop consists of three key Components –
- Hadoop Distributed File System (HDFS) – It is the storage layer of Hadoop.
- Map-Reduce – It is the data processing layer of Hadoop.
- YARN – It is the resource management layer of Hadoop.
HDFS
Hadoop HDFS also stated Hadoop Distributed File System is a distributed file system which provides storage in Hadoop in a distributed manner.
In Hadoop Architecture on the master node also called as namenode is the home for HDFS. On entire attached nodes or systems act as slaves also called datanodes. Name node is responsible for storing metadata of all the nodes attached to the cluster and manages the data nodes. Whereas data node stored the data in a distributed manner in it.
HDFS is distributed, scalable and highly fault-tolerant file system for data storage. By default distribution factor or replication factor is 3, which means the stored data is segregated three times in the cluster across all number of nodes. Further data node split that data into data blocks. By default size of data block is 128MB.
Hadoop Architecture: –




For eg. Suppose you have a file of 500MB and your Hadoop cluster is three node cluster that means one name node and two data nodes. Replication factor is 2.
MapReduce
Map reduce is the heart of the Hadoop, It is a programming model to communicate with Hadoop. It is designed for handling large volumes of data in with parallel processing by dividing the small processes across the system.
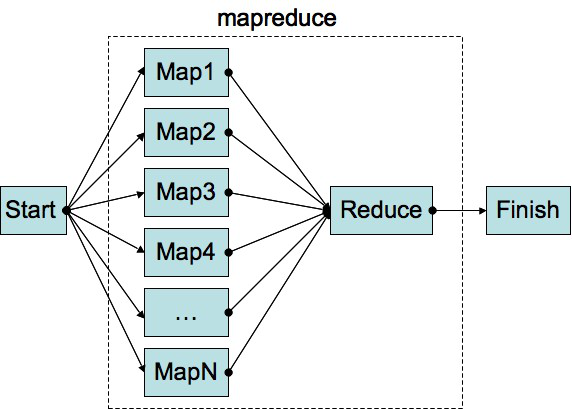
Hadoop MapReduce is a framework for distributed processing of huge volumes of data set over a cluster of nodes. The data stored as distributed manner in HDFS which help the MapReduce to perform parallel processing quite effectively.
YARN
YARN – Yet Another Resource Negotiator is the resource management layer of Hadoop. While using multi-node cluster it is very difficult to manage/allocate the resources like memory and processor (system). Hadoop Yarn manages the resources quite efficiently.
Yarn runs on the master node or name node that process is known as Resource Manager and for data nodes that process is called Node Manager.
Hadoop Installation: –
Hadoop usually supports Linux platform. Therefore, a Linux operating system is required for setting up Hadoop environment. If you have windows OS, you can still install a VMware software in it and have Linux inside the VMware.
So, I am not discussing detailed installation process which is easily available on many other websites to setup single node or multi-node Hadoop cluster. Still, I’ll mention software required to setup cluster.
Java Installation: –
As we know Hadoop is written in Java. So, java environment is required for running smoothly.
You can check whether Java is installed or not with the above command in Linux shell command.
After setting up the java environment now is the time to download the latest version of Hadoop 3.0 from this address http://Hadoop.apache.org/releases.html .
Setting Hadoop Environment: –
- For all software environment, setup details are written in ~/.bashrc file in Linux.
- Extract the downloaded Hadoop zip file then place the folder best fitted location.
- Give the folder all the read, write and execute permission with below command for smooth processing.
Bashrc File:-
Hadoop Configuration: –
All configuration file is available under /Hadoop3.0/etc/Hadoop folder path.
Core–site.xml:-
To view the progress of Hadoop cluster like on which port number the cluster is running, file system and etc.
Hdfs-site.xml: –
This file contains information about the replication factor. Here you can decide how many times you want to replicate file across the cluster. Namenode and datanode address where all the files are going to be save.
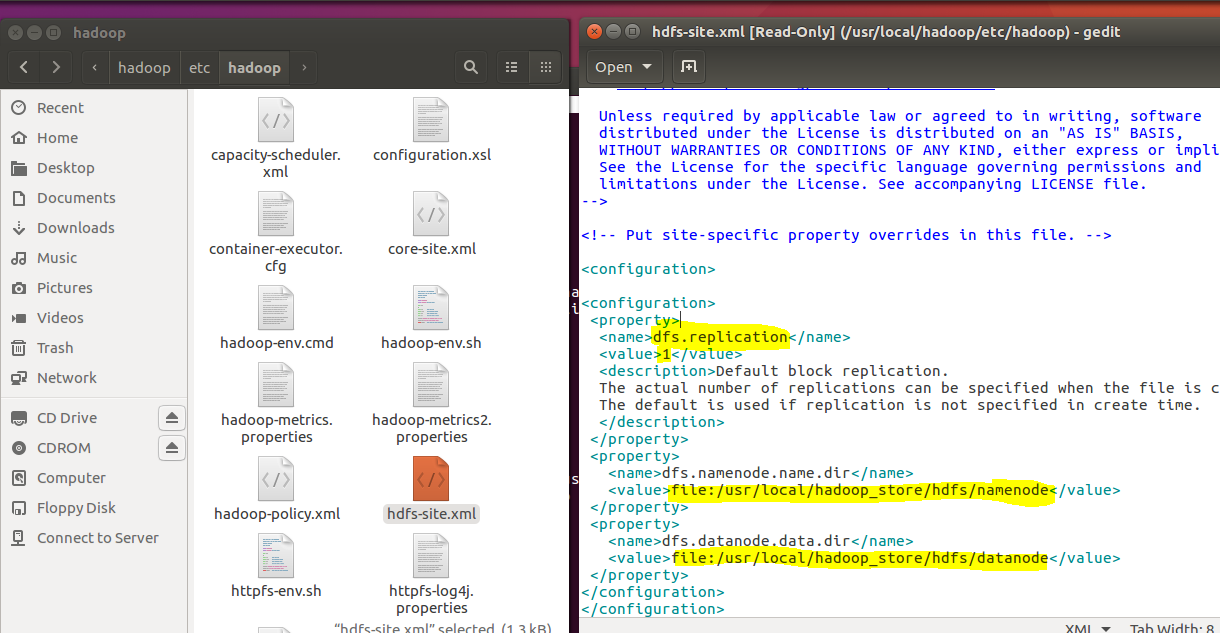
mapred-site.xml :-
By default this file contains yarn template in the value section yarn, that means Hadoop will use the yarn framework for data processing which I will discuss later as Hadoop daemons.
Namenode setup: –
After configuring Hadoop files now is the time to verifying the file and setup namenode for the cluster.
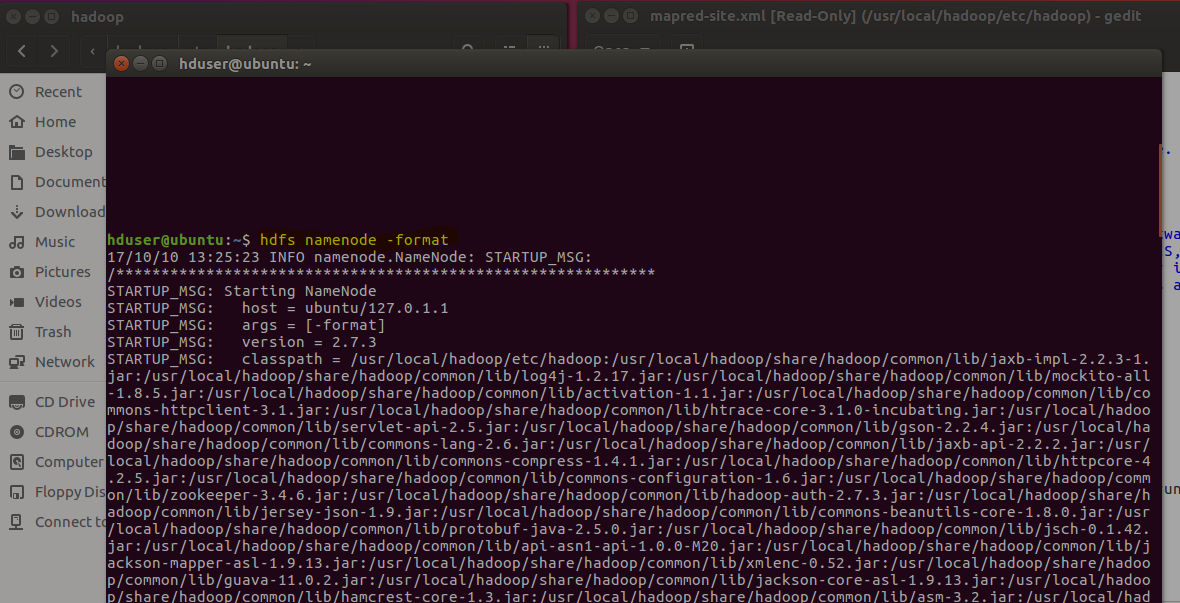
So in this command format the namenode folder which is already blank initially.
Starting Hadoop Cluster: –
$ Start-dfs.sh
After running this command firstly, we need to verify all the process is running or not if any of the one Hadoop processes is not running. Then we need to figure it out by repeating the process where we have encountered the error.
Hadoop Daemons (Process)
- Namenode– It runs on master node for HDFS. Responsible for storing metadata of files distributed across cluster holding information like location, permission, no of block used and more.
- SecondaryNamenode: – This process also runs on master node or it can also run on separate system also. As the name indicates secondary also called backup node. When namenode get update, then secondary node gets update automatically with the latest information.
- Datanode– It runs on slave nodes for HDFS.
- ResourceManager:- The ResourceManager is responsible for the availability of resources and runs several critical services, the most important of which is the Scheduler.
- Scheduler
Scheduler is a component of the YARN ResourceManager which allocates resources to running applications. It does not monitor the application status. It will not instantiate the task if some task is stop executing.
- NodeManager– It runs on slave node for Yarn. Periodically communicating with the ResourceManager and share information about the process completion status. Conceptually, NodeManagers are much like TaskTrackers in earlier versions of Hadoop.
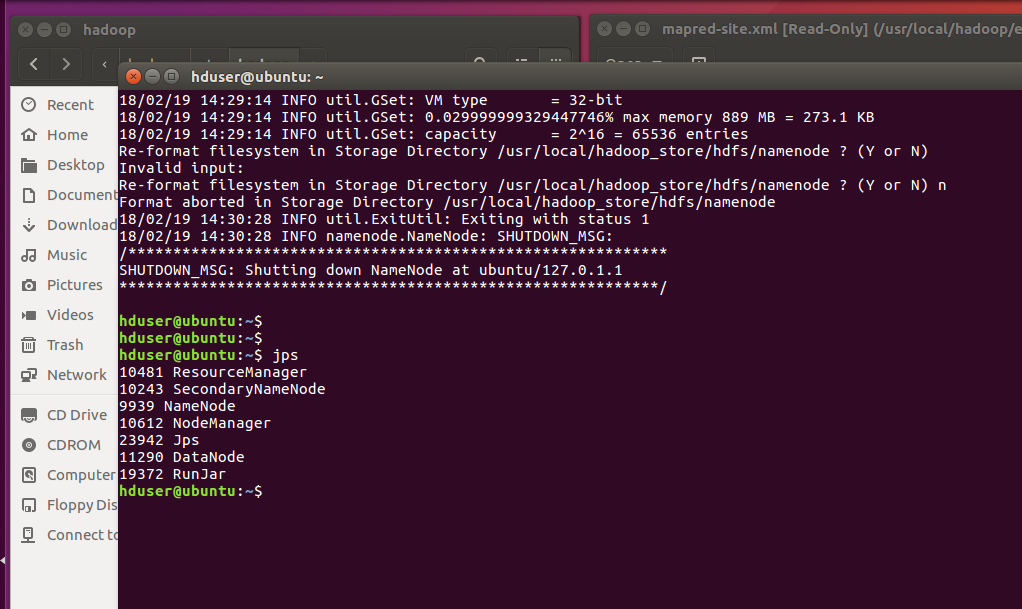
As the screenshot display all the Hadoop daemons are running now you can view information of those processes in web browser.
Verification of Cluster: –
After above command finishes, you can view the cluster information on the port number which we set up in core site xml file in this case I have used 50070. Below is the image of cluster information.
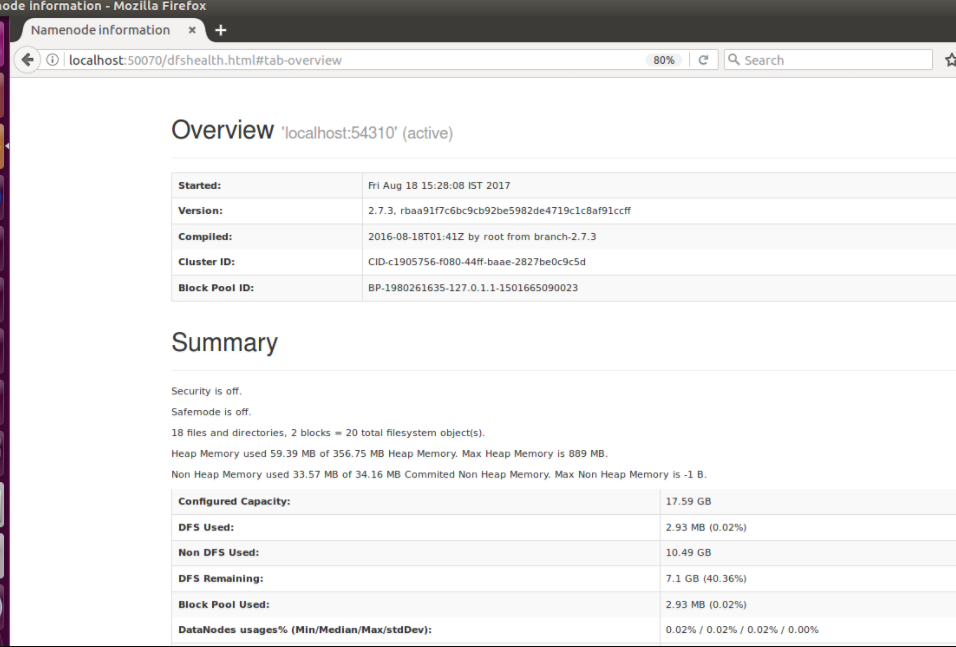
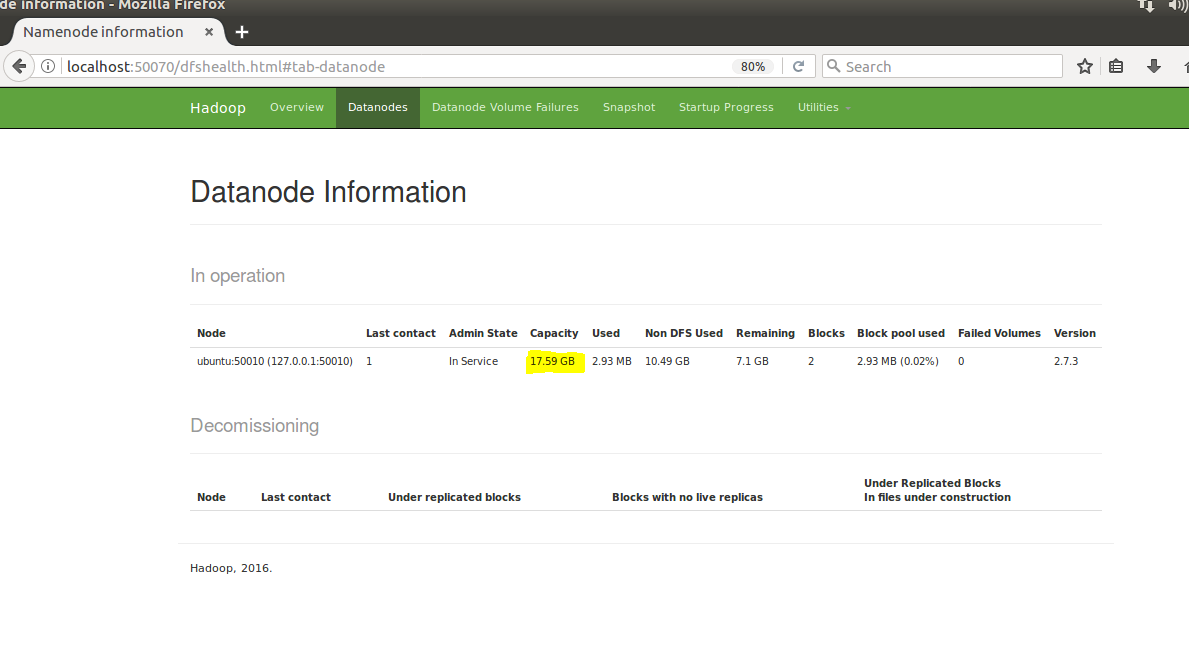
DataNode: –
The screenshot displays the datanode attached in the cluster.Because, it will display memory size and used memory and free space.
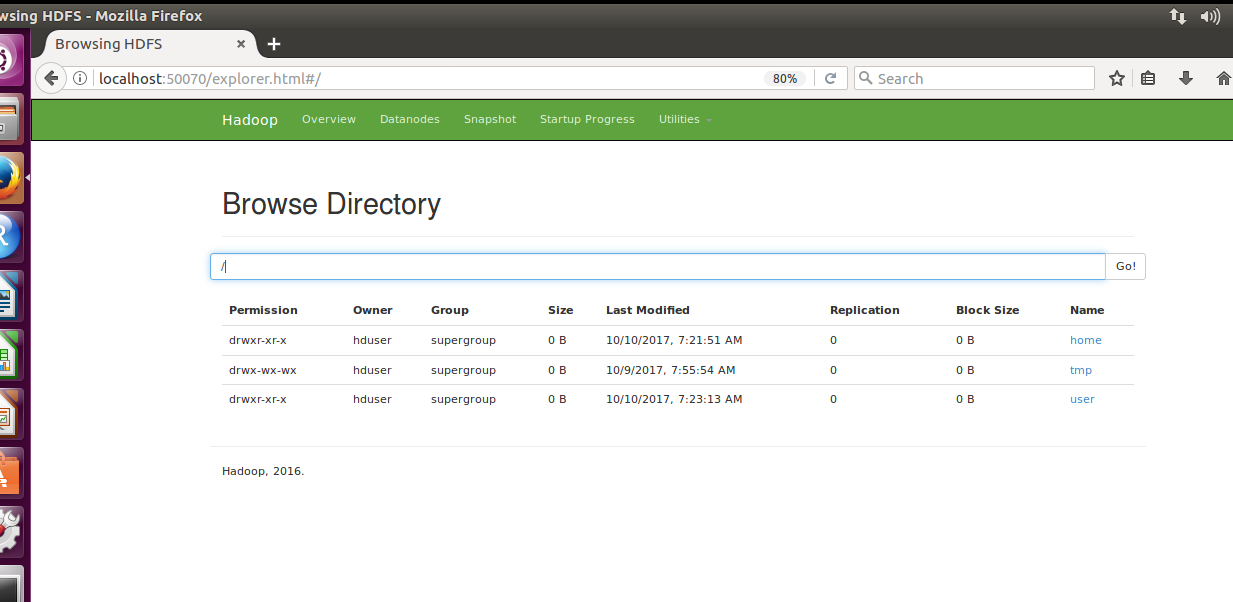
 Directory Structure: –
Directory Structure: –
 Directory Structure: –
Directory Structure: –We can also view the file system of Hadoop files saved in the environment
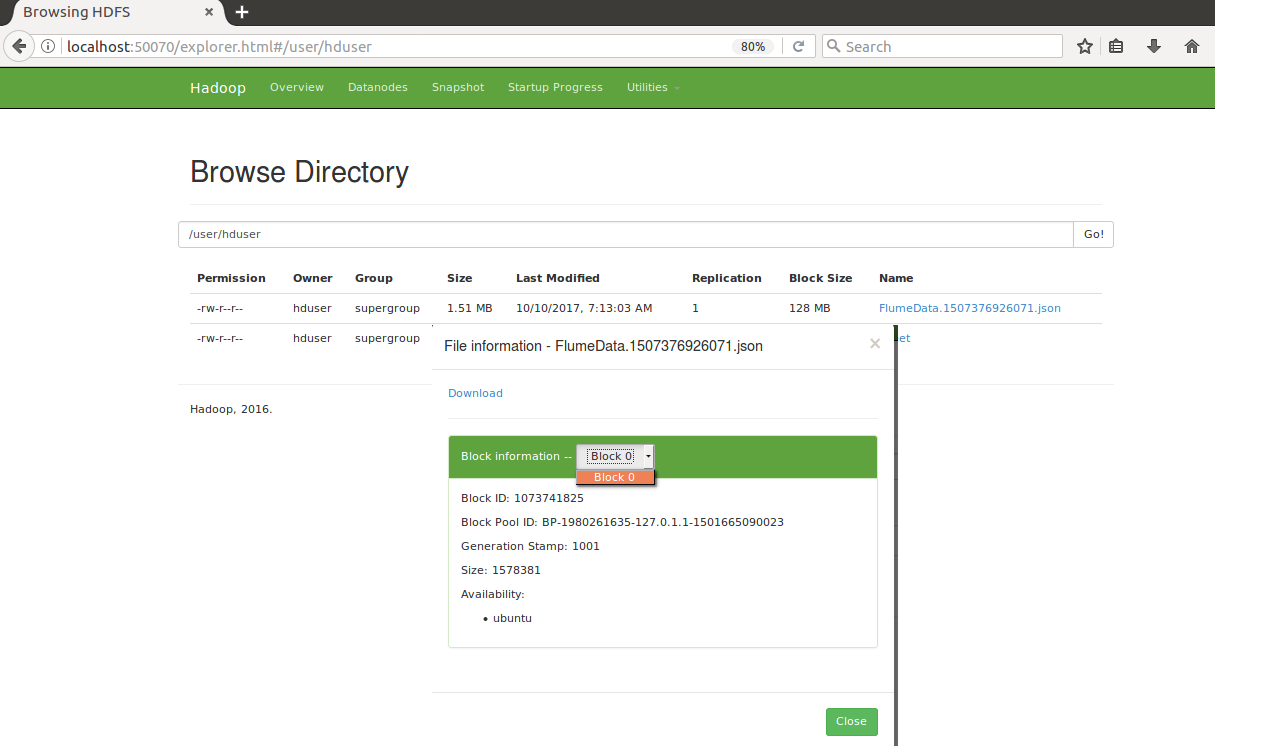
Below screenshot display the flume file having size of 1.51MB using only one block because the file size is smaller than default block size which is 128 MB.
Above installation process is to use parallel processing with Java MapReduce program. If you want other Hadoop components for the ease then you can use any of the Hadoop tools in Hadoop environment.
Hadoop Ecosystem Components
- Hadoop HDFS – Distributed storage layer for Hadoop.
- Yarn Hadoop – Resource management layer introduced in Hadoop 2.x.
- Hadoop Map-Reduce – Parallel processing layer for Hadoop.
- HBase – It is a column-oriented database that runs on top of HDFS. It is a NoSQL database.
- Hive – Apache Hive is a data warehousing infrastructure based on Hadoop and this use query big data with the help of sql like query structure.
- Pig – It is a scripting language known as Pig-Latin. Pig enables writing complex data processing scripts without the interference of Java programming language.
- Sqoop – It is a tool design to move a huge amount of data between Hadoop cluster and RDBMS.
- Zookeeper – A centralized service for maintaining configuration information, naming, providing distributed synchronization between the Hadoop cluster services.
- Mahout – A library of scalable of machine-learning algorithms and implemented on top of Apache Hadoop and using the MapReduce java programs.
Advantages of Hadoop: –
Scalable: –
Hadoop is a highly scalable storage framework because it can store and distribute very large data sets across hundreds of systems in parallel. Unlike traditional relational database systems (RDBMS) that can’t scale to process large amounts of data, Hadoop enables businesses to run applications on thousands of nodes involving thousands of terabytes of data.
Cost effective:-
Hadoop also offers a cost-effective storage solution for businesses. The problem with traditional relational database management systems is that because of it is extremely costly for handling huge amount of data. With Hadoop comes into the picture now companies would not delete their past data due to lack of storage and processing softwares.
Flexible: –
Hadoop is efficient to work with different types of data both structured and unstructured to generate value from that data. This means businesses can use Hadoop to derive valuable business insights from data sources such as social media, IOT’s. In addition, You can use Hadoop for a wide variety of purposes, such as log processing, recommendation systems, data warehousing, market campaign analysis and fraud detection.
Fast: –
Hadoop’s own storage technique is based on a distributed file system that basically ‘maps’ data wherever it is located on a cluster. The tools for data processing are often on the same servers where the data is located and resulting in much faster data processing. If you’re dealing with large volumes of unstructured data than Hadoop is able to efficiently process terabytes of data in just minutes, and petabytes in hours.
Resilient to failure: –
A key advantage of using Hadoop is also its fault tolerance. When data encrypts to an individual node, that data also replicates to other nodes in the cluster, which means that in the event of failure, there is another copy available for use at the same time; this architecture provides protection from both single and multiple node failures.
Conclusion: –
The term big data is very broad topic of discussion in today’s world. Use of big data technology like Hadoop is a necessity to the organization who is dealing with huge amount of data. Ease of availability is the main reason why this technology is most popular than other leading technologies. Hadoop environment provides the facilities for other programming languages other than java like python, c++ communicate via Hadoop Streaming. On the other hand, existing Database engineers who use traditional to of writing complex sql queries can use Hive tool in Hadoop environment. The result will be faster than RDBMS.
By implementing Hadoop technology effectively, any organization can get the incredible amount of value from data that is already available. Finally, the main aim of this article is to introduce you to big data technology and components related to it.
I excel when it comes to making bespoke data dashboards and visualizations that users and clients absolutely love. Sharing about things I enjoy doing is my hobby, whether it's about a project, collaboration, feedback, or just simple how-to guides about visualization.
If you have something to ask or share, I'd love to hear from you!
- Business Intelligence Vs Data Analytics: What’s the Difference? - December 10, 2020
- Effective Ways Data Analytics Helps Improve Business Growth - July 28, 2020
- How the Automotive Industry is Benefitting From Web Scraping - July 23, 2020