
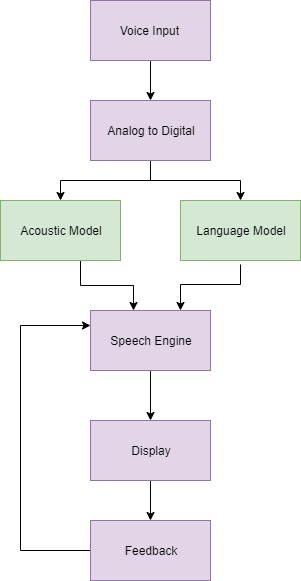
Recognition of speech or speech to text includes capturing and digitizing sound waves, transforming basic linguistic units or phonemes, building phonemic words, and contextually analyzing words to ensure the correct spelling of words that sound the same.
Jump to Section
What is Speech Recognition?
Speech recognition is also known as automatic speech recognition (ASR), computer speech recognition, or speech to text (STT), which means understanding voice by the computer and performing any required task. It develops methods and technologies that implement the recognition and translation of spoken language into text by computers.
Working Mechanism of Speech Recognition
Where Is It Used?
- System control/navigation, e.g., GPS-connected digital maps
- Commercial/industrial applications in the car steering system
- Also, voice dialing hands-free use of mobile in the car
Speech Recognition Techniques
The main objective of speech recognition is for a machine to be able to “listen,” “understand,” and “act upon” the information provided through the voice input. Automatic speaker recognition aims to analyze, extract, characterize, and recognize information about the speaker’s identity.
Hence, the speaker recognition system works in three stages, as follows:
1. Analysis
2. Feature extraction
3. Modeling
2.1 Speech Analysis Technique
Speaker identity can be shown by a different type of information that is present in speech
data. This incorporates speaker-specific information due to the vocal tract, excitation source, and behavior feature. This stage deals with a suitable frame size for segmenting speech signals for further analysis and extracting.
2.2. Feature Extraction Technique
The speech feature extraction technique is the process of placing words in groups or classes is about decreasing the dimensionality of the input vector while maintaining the discriminating power of the signal. From the basic formation of speaker identification and verification system, we know that the number of training and test vector needed for the classification problem grows with the dimension of the given input; therefore, we need feature extraction of the speech signal.
2.3. Modeling
The modeling technique aims to create speaker models using a speaker-specific feature vector. Further, Speaker recognition and Speaker identification are the parts of Modeling. The speaker identification technique identifies by itself, who is speaking based on individual information integrated into a speech signal.
What Is an Acoustic Model?
In brief, an acoustic model is a file that consists of statistical representations of each of the distinguishable sounds that makes up a word. Statistical representations assigned to the label called a phoneme. The English language has approximately 40 different sounds used in speech recognition. Therefore, we have 40 different phonemes.
What Is a Language Model?
In brief, language models are used to limit the search in a decoder by limiting the number of possible worlds that are required to consider at any one point in the search. Finally, the result is faster execution and higher accuracy of the model.
Types of Speech Recognition Softwares
- Speaker Dependent
Those individuals who will be using the system train the Speaker dependent systems. These systems are capable of achieving a high better command count than 95% accuracy for word recognition. The drawback of this approach is that the system only responds accurately only to the individual who trained the system. This is the most common approach implemented in software for personal computers. - Speaker Independent
Speaker independent is a system trained to respond to a word regardless of who is speaking. Therefore the system must respond to a large variety of speech patterns, inflections, and enunciation are of the target word. The command word count is generally lower than the speaker-dependent, whereas high accuracy can still be maintained within processing limits. Industrial requirements need speaker-independent voice systems more often, such as the AT&T system are used in the telephone systems.
Example of Speech Recognition
- Speech Recognition is implemented in the front end or the back end medical document processes. Front end speech recognition is where the provider dictates the speech recognition engine. Spoken words displayed as recognized. The dictator is answerable for editing and signing off the Document. Back end recognition, also known as deferred speech recognition, is where the provider dictates into a digital dictation system. The voice is routed through a speech-recognition machine, and the draft document is recognized. It is routed along with the original voice file to the editor (where the draft file is edited and report finalized). Back end or deferred recognition is widely used in the industry currently.
- Substantial efforts dedicated in the last decade to the test and evaluation of speech recognition in fighter aircraft. Speech recognizers operated successfully in fighter aircraft. Applications like setting radio frequencies, commanding an autopilot system, setting steer-point coordinates and weapons release parameters, and also controlling flight display.
- In-car systems, simple voice commands used to initiate phone calls, select radio stations, or play music from a compatible smartphone, MP3 player, or music-loaded flash drive. In addition, voice recognition capabilities vary between car make and model.
Conclusion
Speech is the primary and most convenient way for people to communicate. We’re at a turning point where voice and natural language understanding are suddenly at the forefront. The main goal of the speech recognition area is to develop techniques and systems for speech input to the machine. Since humans do a daily activity of speech recognition, it is one of the most consolidating areas of machine intelligence. Speech recognition has created a technological impact on society. Further, expected to flourish in this area of human-machine interaction.
With significant advances in voice technologies, users will now need to spend less time performing lengthy searches or transcribing huge voice data to text transcripts. It is imperative that this new technology also establish a new mark in the construction of a brand through new-age voice dynamics enabled by the AI. More innovation can offer companies in the field of speech recognition, a wide horizon of opportunity to explore.
I excel when it comes to making bespoke data dashboards and visualizations that users and clients absolutely love. Sharing about things I enjoy doing is my hobby, whether it's about a project, collaboration, feedback, or just simple how-to guides about visualization.
If you have something to ask or share, I'd love to hear from you!
- Business Intelligence Vs Data Analytics: What’s the Difference? - December 10, 2020
- Effective Ways Data Analytics Helps Improve Business Growth - July 28, 2020
- How the Automotive Industry is Benefitting From Web Scraping - July 23, 2020