
In case you have missed my previous blog version stating an introduction to Mobile Automation explaining the launch of an application using Appium, then I would suggest you go through the same for the basic understanding. proceeding further towards this approach, I have decided to add an informative branch to this tree trunk.
Taking further steps, now you need to learn about automating your test cases and for that, you first need to inspect the elements which are needed to execute the test case.
For this, we have a tool called UIAutomatorViewer which is present in Android SDK folder.
Jump to Section
Steps To Run UIAutomatorViewer
Actually, the name is not enough to explain this tool in a better manner, rather you require a step-by-step tutorial for its better understanding. Here you go…
1.Connect the device with the help of USB to your system.
2.Open cmd and type command “adb devices” in the window. It will display all the connected devices like this,
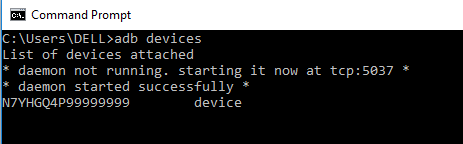
3. It will display a binary name for the device, so there is no need to worry about it.
4. Now, on the actual device open the app which you want to automate. I am giving you the demo of Flipkart app.
5. Browse your Android installation folder and go to the following directory to open UIAutomatorViewer:
Android -> android-sdk -> tools -> uiautomatorviewer.bat
On my machine, the default location of the Android folder is C:\Users\DELL\AppData\Local\Android\sdk\tools\bin
6. Run bat by double click on it, a window will appear like this,
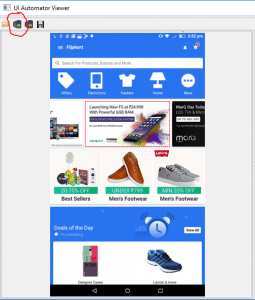
7. Click on Device Screenshot to take a screenshot of your device screen by clicking on the below-marked icon.
Please make sure the application is opened in the device before clicking on this icon.
8. Now, move your mouse pointer on the element which you want to inspect and click on it. You will get all the UI details for that particular element.
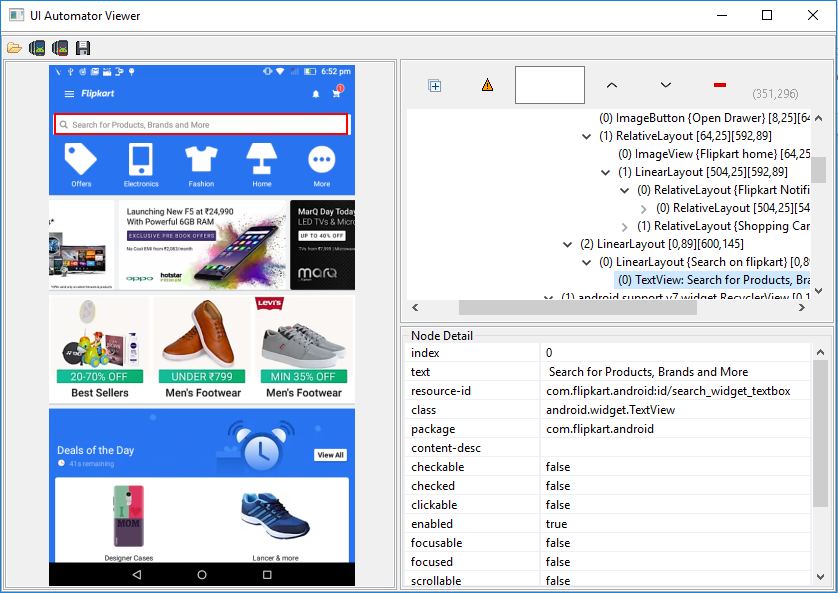
Here, text can be used as name attribute, resource-id as id and there is no need to give the id with the package name you simply copy the text written after id/ and use it.
Usage Of Findelement() And Findelements() Methods
Now after inspecting the element, the next thing to do is to perform some specific actions on these elements. AppiumDriver instance provide findelement() and findelements() methods to interact with different elements.
The difference between Find Elements and Find Element method is findelement() returns a WebElement object otherwise the case is that it throws an exception NoSuchElementException and findelements() returns a list of WebElements. It can also return an empty list if no elements match the query.
The Find methods take a locator or query object called By. ‘By’ strategies are listed below.
By Name
This is also an efficient way to locate an element by name attribute, but again the problem is same as with it that UI developer makes it having non-unique names on a page or auto-generating the names. The first element with the ‘name’ attribute value that matches the location will be returned back easily, with the use of this strategy. If no element has a matching name attribute, a NoSuchElementException will be raised.
e.g. If an element is given like this:
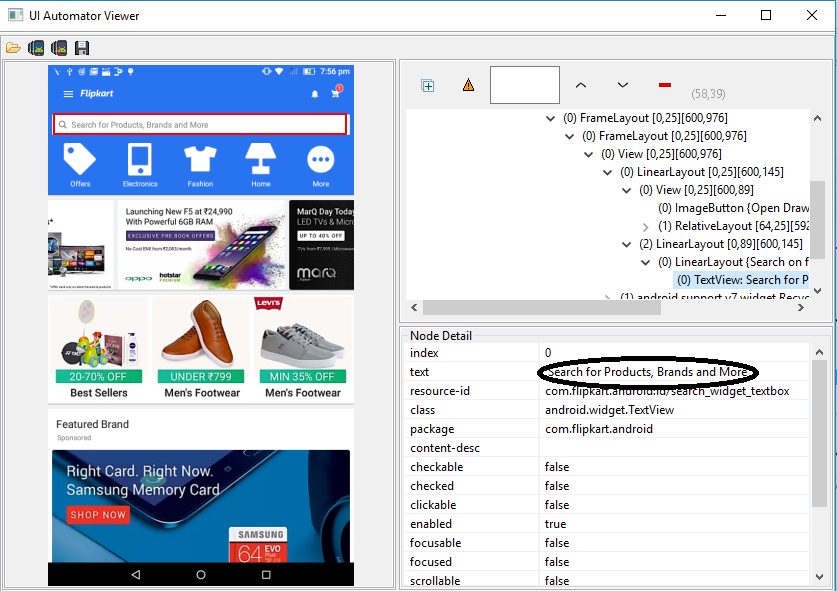
So, it can be used like this,

By Class Name
We can locate elements with the help of this based on the class attribute value. If an element has many classes then this will match against each of them. A class can contain many elements.
e.g. If an element is given like this:
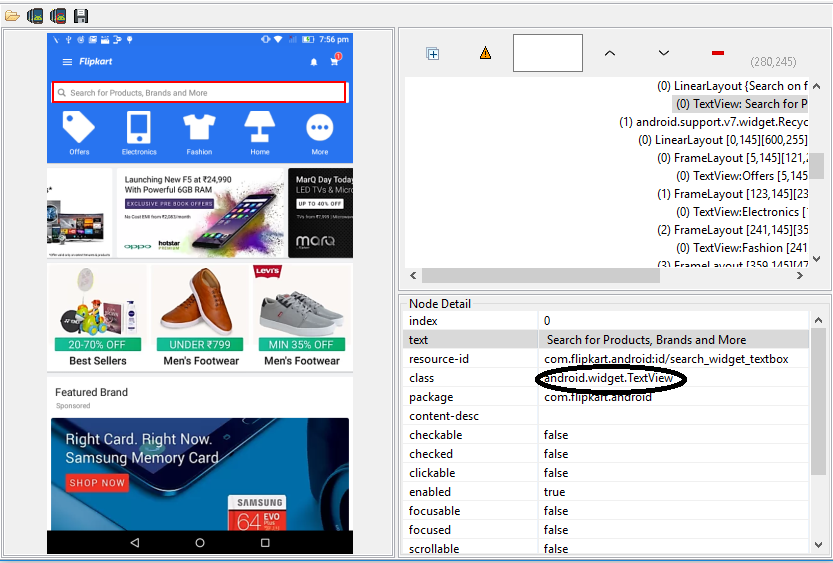
So, it can be used like this,

This locator will only work for you if and only if the class attribute has some unique value.
By ID
We can locate elements with the help of ID locator based on its attribute value. This is the most efficient way to locate the elements because id attribute defines every element uniquely. This is the most preferred way to locate an element, as most of the times IDs are unique.
e.g. If an element is given like this:
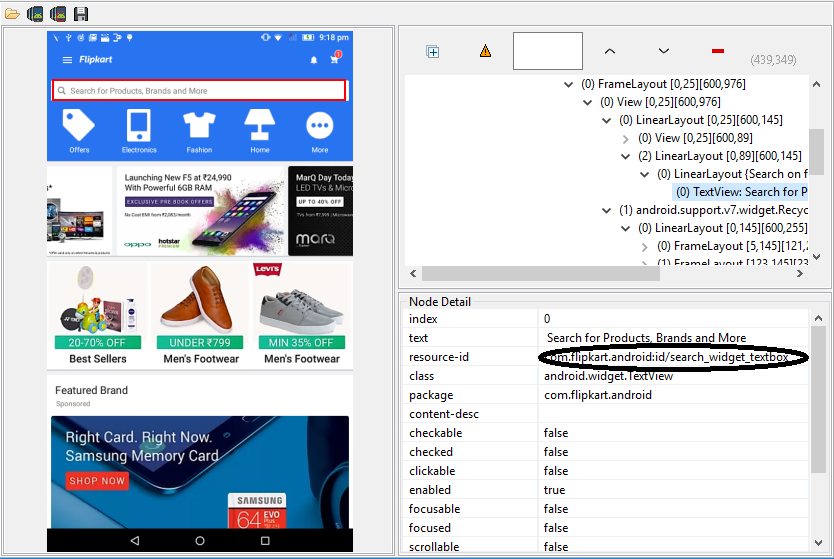
So, it can be used like this,
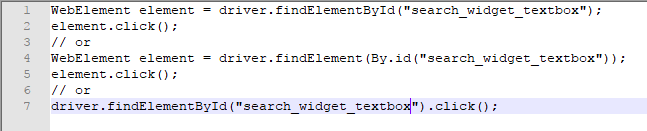
By XPath
As you will end up many situations where you do not have any options but to use XPath. Xpath can be relative and absolute but it is suggested to always use relative XPath because absolute XPath use indexes to locate the element, and it will fail if there are any changes made in the UI of application. So, it’s better to use relative XPath.
Let’s look at the example below for username field of Flipkart Sign In module. We are going to write relative XPath for username text field, as you can see it doesn’t have any id, not any text value attached to it. We only have a class name but the problem is class name is same as username and password field.
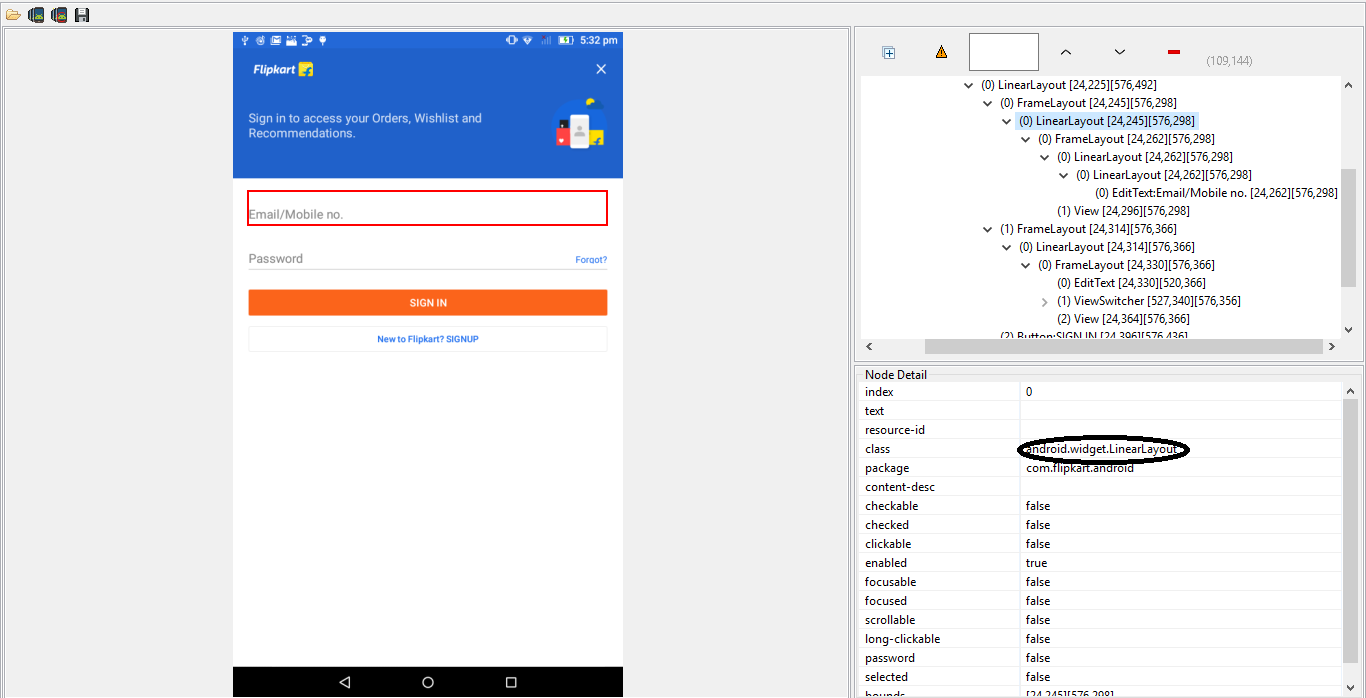
If you inspect username field then you will notice that it has text value as ‘Email/Mobile no.‘ So we can easily traverse down and reach to edit text element.
So we can use XPath like this :
![]()
Locators Preference Wise
As far as I have used these locators and as per my knowledge, the hierarchy is as follows:
- ID
- Name
- className
- XPath
Here, I have given first priority to ID because it will give you a unique attribute value always, name and className locators can have same attribute values for multiple elements. Sometimes Name can give you a unique value but not every time but className will be same for all those elements which are inside a particular class. And, if everything fails then only XPath helps you to locate the element.
XPath provides you some functions so that you can easily find the desired element.
XPath Functions
Below is the functional working of XPath:
contains()
If you have a long text value or attribute value and you only want to use a part of it that time contains() will be the most effective way to fetch a small part of that value.
e.g. – If you have a text containing “Sign In to access your account” and you only want to access a small part of it, then the syntax for the XPath using contains function will be, “//*[contains(text(),’Sign In’)]”.
If you want to use some attribute value, you can use it like this “//*[contains(@attribute name,’ part of attribute value’)]”.
text()
Another option which you can use is text(), but you have to use complete text value if you are using this function.
e.g. – If you have text value as “Sign In” then the syntax will be. “//*[text()=’Sign In’]”
starts-with()
You can use it by using the initial starting value of the given text. If you have text as “Enter Password”.
Syntax: //*[starts-with(@attribute name, ‘Enter’)]
following-sibling
When you want to traverse to the next sibling i.e. the next tag which is on the same level, then you can do it by using it.
e.g. – //span[contains(text(), ‘ABZ’)]/following-sibling::section/span[@name=’edit’]
preceding-sibling
When you want to traverse to the previous sibling i.e. the previous tag which is on the same level, then you can do it by using it.
e.g. – “//ul/li[contains(text(),’Apple Mobiles’)]/preceding-sibling::li”
The above-mentioned functions of XPath are mainly used to find the elements.
By using UIAutomatorViewer you can easily inspect the elements and in order to uniquely identify them, you can use the above-mentioned locators. As you can analyze, you now have multiple options to uniquely identify the elements. So just click on to your idea and get started!
- COVID-19: How We Are Dealing With It as a Company - March 23, 2020
- Agile Testing – The Only Way to Develop Quality Software - February 8, 2019
- How to Perform System Testing Using Various Types Techniques - May 16, 2018