
Web Scraping (also termed Screen Scraping, Web Data Extraction, Web Harvesting etc.) is a system to extricate a lot of information from sites whereby the information is removed and spared to a nearby record on your PC or to a database in tabular format.
Ahh, that’s a known one..right? Well, then let’s know the need of doing so…
Data displayed by most websites can only be viewed using a web browser. These web browsers do not provide the functionality to save a copy of this data for our personal use. The only option then left is to manually copy and paste the data which is a very tedious job that can take many hours or sometimes days to complete it. But, worry no more because Web Scraping is the technique of automating this process that makes your job much easier than before.

But,
How do we scrape a website?
What are the essential things we have to do before scraping a website?
What are the requirements to start scraping?
I am sure this is the queue of interrogations coming next in your mind. So, let’s figure them out!

Before writing the script for the website, there are some points you must have to do which makes your scraping easier. Let’s have a look at them:
Jump to Section
Analyze Your Website
Every new project needs a pre-analysis so that we can gather the essential requirements and information to start our new project. In web scraping, it is very important to analyze your website. Basically, pre-analysis of a website means finding the complexity of that website.
Define Complexity Level

Complexity level depends on the website nature. It can be simple, moderate, high or very high. There are some terms to define the complexity of a website like :
- Simple Level complexity means we easily get details from the Website Source directly, no need of formatting the URLs, no need of Login into the website by web browser control, the website does not get block.
- Moderate Level complexity means we are not able to get the information from the website easily, we require cookies, the need of formatting the URLs.
- High Level complexity means when we are not able to get the content from the website easily, require any type of cookies and also need any post value and any referrer, the need of Formatting the URLs, need to Login into the website by web browser control, the website gets block frequently.
- Very High Level Complexity means when we are not able to get the content from website easily, all the desire details are not available in the content, need any type of cookies, any post value, any referrer is must, need of formatting the URLs and each time we need to append some new values in it to get the proper content, need of Login into website more than one time, need of Timer control and we have to stop and start it again and again in code.
Finding Data Source
Finding data source of a website is a very crucial task in web scraping. Every website has its own type of data source like some websites have their data in HTML pages, some websites use json coding to bind their data with HTML pages, and some websites use APIs to get their data from another source. If we get the URLs of that data source then it will be easy for us to extract data from them.
Use Proxy Servers
Sometimes when we are scraping a website, some website servers block our IP address because they detect some anomalous activity. The reason behind this is we frequently hit that website to get its data. To avoid that we use proxy servers. A proxy server is an intermediary between your PC or device and the Internet. This server makes solicitations to websites, servers and services on the Internet for you.
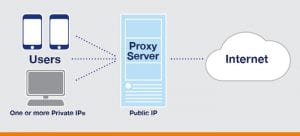
When you load a website on the Internet, you have a direct connection to the Internet and the server where it is hosted. At that time the host of that website can see your IP address. With the help of this address it can approximate your geographical location. Also, the browser sends its user agent information and the website knows what browser you are using. On top of this, cookies are stored on your computer which provide further personal information.
Proxy servers can hide your IP address (if they are set to do this), can send a different user agent so that your browser is not identified and can block cookies or accept them but not pass them to your PC or device.
Therefore, when using a proxy server, you can be a lot more anonymous than when using a direct connection to the Internet.
Avoid Conditional Statements
Developers tend to utilize a considerable measure of restrictive articulations in their code. Obviously, each stream has one particular way, its own particular approvals, and so forth. It is very natural that your code has a lot of decisions to be made at runtime.
But, sometimes when you are downloading data from a website, at that time every single unit of data has to cross those decisions whether there is any need for those decisions for any particular unit of data or not which causes a lot of time to execute those statements. When statements take a lot of time to execute which causes slow downloading of data.
Script Updation
Before start downloading your data, always check or verify is there any changes in your website or not. Because when you scrape a website (which is already scrapped before) after a long time, there may be or may not be happen any changes in that website which tends to download your data incorrect.
So, before downloading a website check all the possibilities in which validation may be possible.
My Point Of View…
Patience is something that you will need in abundance if you plan on executing a web scraping project. Due to the ever-changing nature of websites, there is no way to create a single script that will continue to provide you with data for a long time.Maintenance will be a part of your life if you are managing a web crawler yourself.
And following these best practices will help you stay away from issues like blocking and legal complications faced while scraping!
- LinkedIn Scraper | LinkedIn Data Extractor Software Tool - February 22, 2021
- Is Web Scraping Legal? - February 15, 2021
- What Is Data Scraping? - February 10, 2021