INTRODUCTION:
Topic Modeling as the name suggests is one such technique in the field of Text Mining which automatically identifies the topic present in a text object, and also drive the hidden patterns exhibited by a text corpus.
In recent years, With the growing amount of data in, that too mostly unstructured, it’s difficult to obtain the relevant and desired information. Hence, technology has developed some powerful methods which can be used to mine through the data and fetch the information that we are looking for as Analytics Industry is all about obtaining the “Information” from the data.
Let’s discuss further on ‘How to do topic modeling in python’ using python packages.
Topic modeling is the technique to get the all hidden topic from the huge amount of text document. Latent Dirichlet Allocation(LDA) is the very popular algorithm in python for topic modeling with excellent implementations using genism package. However, In order to extract the best quality of topics that are meaningful and clear, then, it depends on the heavy and quality cleaning of the text preprocessing strategy to find an optimal and useful number of topics.
Jump to Section
Here’s a tutorial that would explain to you all the techniques used in Topic Modelling
To start with, Natural programming language(NLP) is known to be the best primary application as it automatically gets to the Topic of discussion that people are involved through a large amount of text. Like, social media, customer reviews of hostels, movies, product reviews etc are some of the examples that involve a large amount of text and so can’t be analyzed.
we can only read the limited text of feedbacks or reviews as it really becomes hard to read such a large volume of text and compile the topic. so, to make things easy we require an automated algorithm that can read all the documented text and get the output from the required topic.
Here’s another example of Amazon product review datasets.
To, discuss further on this Topic I will be using LDA to extract the naturally discussed topics.
Then, I will use Latent Dirichlet Allocation (LDA) from Gensim package of python.
and following to that, we will also extract the volume and percentage contribution of each topic an idea of how important a topic is.
Table of Content
-Latent Dirichlet Allocation for Topic Modeling
-Parameters of LDA
-Python Implementation
-Preparing documents
-Cleaning and Preprocessing
-Preparing document term matrix
-Running LDA model
Results
-Tips to improve results of topic modeling
-Frequency Filter
-Part of Speech Tag Filter
-Batch Wise LDA
-Topic Modeling for Feature Selection
Running in python
Preparing Documents
Here are the sample documents combining together to form a corpus.
Download nltk stopwords and space model:
We would need the ‘stopwords’ from NLTK and ‘spacy model’ for the text pre-processing.
This is used for cleaning the data/text. Later, we will be using the space model for lemmatization.
# Run in python console
import nltk; nltk.download('stopwords')
# Run in terminal or command prompt
python3 -m spacy download enImport Required Packages:
Lemmatization is used for converting a word to its root word.
For example, the lemma of the word ‘reads’ is ‘read’. Likewise, ‘words’ –> ‘word’ and so on.
from __future__ import print_function import pandas as pd import gensim from gensim.utils import simple_preprocess from gensim.parsing.preprocessing import STOPWORDS from nltk.stem import WordNetLemmatizer, SnowballStemmer from nltk.stem.porter import * from nltk.stem.lancaster import LancasterStemmer import numpy as np import operator np.random.seed(2018) import sys import nltk import matplotlib.pyplot as plt import csv, os
What Is LDA:
- LDA or latent Dirichlet allocation is really a “generative probabilistic model” of a collection of composites made up of parts.
- Here, the composites are documents and the parts are words and/or phrases (n-grams) with regards to topic modeling.
- However, you may apply LDA to DNA and nucleotides, pizzas and toppings, molecules and atoms, employees and skills, or keyboards and crumbs and so on.
- The probabilistic topic model estimated by LDA contains two tables (matrices).
- The 1st table describes the probability or chance of selecting a certain part when sampling a certain topic (category).
- The 2nd table describes the possibility of selecting a certain topic when sampling a certain document or composite.
Import Amazon product review Data:
We will be using the Amazon product review dataset for this exercise. This version of the dataset contains about 23K reviews data from comment topics. This data is available on Amazon website.
Now for exercise, I will attached data set file
This is imported using CSV package,read_csv and the resulting dataset has many columns.
#import csv file using this
data = pd.read_csv('input.csv', error_bad_lines=False)
data_text = data[['DESCRIPTION']] data_text['index'] = data_text.index documents = data_text
Data Pre-processing:
We will perform all the following steps given below on the dataset:
- Tokenization:
– Split the entire text into sentences and then, the sentences into words.
– We need to change the words in Lowercase and remove punctuation on the text.
– Now, Words that have fewer than 3 characters are removed.
– All the stopwords are removed.
– Words are lemmatized by changing from the first form to the third form.
– Verbs in the past and future tenses are changed into the present.
– Stemmed words are reduced to their root form.
Now, Loading gensim and nltk libraries as shown below:-
nltk.download('wordnet')
def lemmatize_stemming(text):
#stemmer.stem(WordNetLemmatizer().lemmatize(text, pos='v'))
lancaster_stemmer = LancasterStemmer()
return lancaster_stemmer.stem(text)
def preprocess(text):
text=str(text)
result = []
for token in gensim.utils.simple_preprocess(text):
if token not in gensim.parsing.preprocessing.STOPWORDS and len(token) > 3:
result.append(lemmatize_stemming(token))
return result
Document preview after preprocessing:
doc_sample = documents[documents['index'] == 44140].values[0][0]
#print('original document: ')
words = []
for word in doc_sample.split(' '):
words.append(word)
#print(words)
#print('\n\n tokenized and lemmatized document: ')
#print(preprocess(doc_sample))
processed_docs = documents['DESCRIPTION'].map(preprocess)
#print(processed_docs[:10])
Bag of Words on the Text:
All the text documents combined is known as the corpus. To run any mathematical model on text corpus, it is a good practice to convert it into a matrix representation. LDA model looks for repeating term patterns in the entire DT matrix. Python provides many great libraries for text mining practices, “gensim” is one such clean and beautiful library to handle text data. It is scalable, robust and efficient. Following code shows how to convert a corpus into a document-term matrix.
- Creating a dictionary from ‘processed_docs’ which carries the details of how many times a word has appeared in the training set.
- Then, ‘Gensim filter_extremes’ filter out tokens that appear in less than 15 documents (absolute number) or more than 0.5 documents (fraction of total corpus size, not absolute number).
- After following the above two steps, keep only the first 100000 most frequent tokens.
Gensim ‘doc2bow’ words to know as how many times those words have appeared. Save this to ‘bow_corpus’, then check the selected document.
TF-IDF
- Create tf-idf model object using models.
- ‘Tf-idf’ Model on ‘bow_corpus’ and save it to ‘tf-idf’, then, apply the transformation to the entire corpus and call it ‘corpus_tfidf.
- Finally, we preview TF-IDF scores for our first document.
dictionary = gensim.corpora.Dictionary(processed_docs)
count = 0
for k, v in dictionary.iteritems():
#print(k, v)
count += 1
if count > 100:
break
dictionary.filter_extremes(no_below=15, no_above=0.5, keep_n=100000)
bow_corpus = [dictionary.doc2bow(doc) for doc in processed_docs]
wordCountArr=[]
wordCountDict={'word':''}
for j in range(len(bow_corpus)):
for i in range(len(bow_corpus[j])):
#print("Word {} (\"{}\") appears {} time.".format(bow_corpus[j][i][0],
dictionary[bow_corpus[j][i][0]],bow_corpus[j][i][1]))
wordCountDict[dictionary[bow_corpus[j][i][0]]]=bow_corpus[j][i][1]
cd = sorted(wordCountDict.items(), key=operator.itemgetter(1), reverse=True)[:10]
from gensim import corpora, models
tfidf = models.TfidfModel(bow_corpus)
corpus_tfidf = tfidf[bow_corpus]
from pprint import pprint
for doc in corpus_tfidf:
#pprint(doc)
break
Train our LDA model using gensim models:
- Train our data to LDA model using gensim.
- save it to lda_model
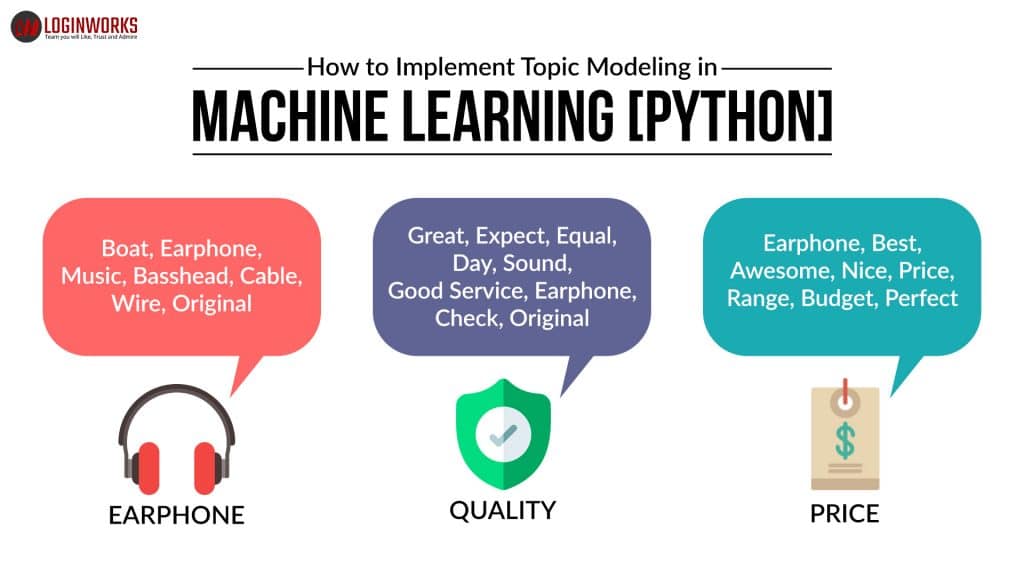
- For each topic, we will explore the words occurring in that topic and its relative weight.Can you distinguish different topics using the words in each topic and their corresponding weights?
Our test document has the highest probability to be part of the topic that our model assigned.
lda_model = gensim.models.LdaMulticore(bow_corpus, num_topics=10, id2word=dictionary, passes=2, workers=1)
topicArr=[]
xAxis=1
YAxis = 1
countLoop=1
with open('C:/amazon-scraper-python/topic.csv', 'a', encoding='utf-8') as csvfile:
filewriter = csv.writer(csvfile, delimiter=',', quoting=csv.QUOTE_MINIMAL)
wordCountDisct=0
for idx, topic in lda_model.print_topics(-1):
filewriter.writerow(
[idx, re.sub(r'[0-9]+[.*]', '', topic),AfterSorted[wordCountDisct][0],AfterSorted[wordCountDisct][1]])
topicText=re.sub(r'[0-9]+[.*]', '', topic)
topicText.replace('"', ',')
#topicArr.append(re.sub(r'[0-9]+[.*]', '',topic))
plt.axis([0, 100, 0, 10])
if(countLoop ==1):
plt.text(3, 2,topicText,
wrap=True, style='italic',
bbox={'facecolor': 'green', 'alpha': 0.5, 'pad': 10}
)
if (countLoop == 2):
plt.text(3, 5, topicText,
style='italic',rotation=15,
bbox={'facecolor': 'red', 'alpha': 0.5, 'pad': 10},wrap=True)
plt.annotate('annotate', xy=(2, 1), xytext=(3, 4),
arrowprops=dict(facecolor='black', shrink=0.05))
if (countLoop == 3):
plt.text(5, 4, topicText, style='italic',
bbox={'facecolor': 'green', 'alpha': 0.5, 'pad': 10},wrap=True)
if (countLoop == 4):
plt.text(10, 6, topicText, style='italic',
bbox={'facecolor': 'blue', 'alpha': 0.5, 'pad': 10},wrap=True)
if (countLoop == 5):
plt.text(4, 8, topicText, style='italic',
bbox={'facecolor': 'yellow', 'alpha': 0.5, 'pad': 10},wrap=True)
if (countLoop == 6):
plt.text(6, 10, topicText,style='italic',
bbox={'facecolor': 'green', 'alpha': 0.5, 'pad': 10},wrap=True)
countLoop +=1
wordCountDisct +=1
print('Topic: {} \nWords: {}'.format(idx, topic))
plt.show()
csvfile.close()
for index, score in sorted(lda_model[bow_corpus[4310]], key=lambda tup: -1*tup[1]):
print("\nScore: {}\t \nTopic: {}".format(score, lda_model.print_topic(index, 10)))
for index, score in sorted(lda_model_tfidf[bow_corpus[4310]], key=lambda tup: -1*tup[1]):
print("\nScore: {}\t \nTopic: {}".format(score, lda_model_tfidf.print_topic(index, 10)))
unseen_document = 'best product of amazon'
bow_vector = dictionary.doc2bow(preprocess(unseen_document))
for index, score in sorted(lda_model[bow_vector], key=lambda tup: -1*tup[1]):
print("Score: {}\t Topic: {}".format(score, lda_model.print_topic(index, 5)))
After running this code it will write data into your CSV file with 10 number of topics and 10 highest occurrence word in file text.
Conclusion
With this, we come to this end of tutorial on Topic Modeling in python Machine Learning. I hope this will help you to improve your knowledge to work on text data. To reap the maximum benefits out of this tutorial, I’d suggest you practice the codes side by side and check the results. I am sharing the link for web scraping code and topic modeling code, you may also, download from this link- https://github.com/vijaykumar91/topic-modeling-machinelearnig.
If have you any further query, Kindly write to me in the comment section.
Thank You and Keep Learning!!!
- What Products Should You Sell on Amazon? - November 18, 2020
- 10 Reasons Why You Should Start Selling on Amazon - October 22, 2020
- Comparative Study of Top 6 Web Scraping Tools - September 3, 2020